
Définition de l'algorithme de décalage moyen
L'algorithme de décalage moyen relève d'un apprentissage non supervisé qui est classé comme l'algorithme de clustering. L'idéologie de l'algorithme Mean Shift est qu'il attribue itérativement des points de données aux clusters en se déplaçant vers le point qui a le point de densité le plus élevé (Mode). La logique sous-jacente du décalage moyen est basée sur le concept d'estimation de la densité du noyau appelé KDE.
Regroupement d'algorithmes à décalage moyen
Une technique d'apprentissage non supervisée découverte par Fukunaga et Hostetler pour trouver des clusters:
- Mean Shift est également connu comme l'algorithme de recherche de mode qui attribue les points de données aux clusters d'une manière en décalant les points de données vers la région à haute densité. La densité de points de données la plus élevée est appelée modèle dans la région. L'algorithme Mean Shift a des applications largement utilisées dans le domaine de la vision par ordinateur et de la segmentation d'images.
- KDE est une méthode pour estimer la distribution des points de données. Cela fonctionne en plaçant un noyau sur chaque point de données. Le noyau en terme mathématique est une fonction de pondération qui appliquera des pondérations pour des points de données individuels. L'ajout de tout le noyau individuel génère la probabilité.
La fonction noyau est requise pour remplir les conditions suivantes:
- La première exigence est de s'assurer que l'estimation de la densité du noyau est normalisée.
- La deuxième exigence est que KDE soit bien associé à la symétrie de l'espace.
Deux fonctions de noyau populaires
Voici les deux fonctions de noyau populaires utilisées:
- Noyau plat
- Noyau gaussien
- En fonction des paramètres du noyau utilisés, la fonction de densité résultante varie. Si aucun paramètre de noyau n'est mentionné, le noyau gaussien est invoqué par défaut. KDE utilise le concept de fonction de densité de probabilité qui aide à trouver les maxima locaux de la distribution des données. L'algorithme fonctionne en faisant les points de données pour s'attirer les uns les autres, ce qui permet aux points de données vers la zone de haute densité.
- Les points de données qui tentent de converger vers les maxima locaux seront du même groupe de grappes. Contrairement à l'algorithme de clustering K-Means, la sortie de l'algorithme Mean Shift ne dépend pas d'hypothèses sur la forme du point de données et le nombre de clusters. Le nombre de clusters sera déterminé par l'algorithme par rapport aux données.
- Afin d'effectuer l'implémentation de l'algorithme Mean Shift, nous utilisons le package python SKlearn.
Implémentation de l'algorithme Mean Shift
Voici l'implémentation de l'algorithme:
Exemple 1
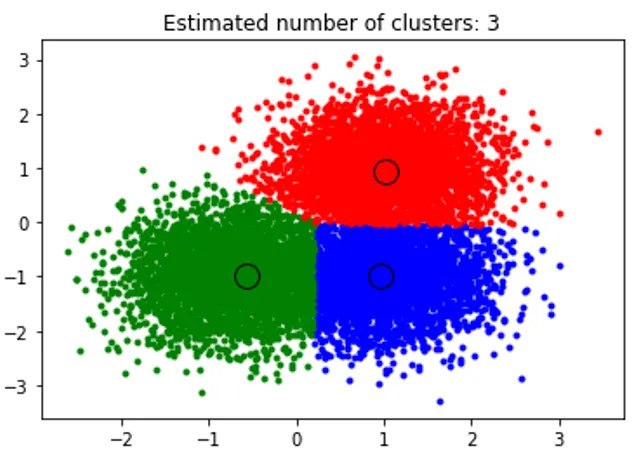
Basé sur le didacticiel Sklearn pour l'algorithme de clustering à décalage moyen. Le premier extrait implémentera un algorithme de décalage moyen pour trouver les grappes de l'ensemble de données bidimensionnelles. Packages utilisés pour implémenter l'algorithme de décalage moyen.
Code:
fromcluster importMeanShift, estimate_bandwidth
from sklearn.datasets.samples_generator import make_blobs as mb
importpyplot as plt
fromitertools import cycle as cy
Une chose clé à noter est que nous utiliserons la bibliothèque make_blobs de sklearn pour générer des points de données centrés sur 3 emplacements. Afin d'appliquer l'algorithme de décalage moyen aux points générés, nous devons définir la bande passante qui représente l'interaction entre la longueur. La bibliothèque de Sklearn a des fonctions intégrées pour estimer la bande passante.
Code:
#Sample data points
cen = ((1, .75), (-.75, -1), (1, -1)) x_train, _ = mb(n_samples=10000, centers= cen, cluster_std=0.6)
# Bandwidth estimation using in-built function
est_bandwidth = estimate_bandwidth(x_train, quantile=.1,
n_samples=500)
mean_shift = MeanShift(bandwidth= est_bandwidth, bin_seeding=True)
fit(x_train)
ms_labels = mean_shift.labels_
c_centers = ms_labels.cluster_centers_
n_clusters_ = ms_labels.max()+1
# Plot result
figure(1)
clf()
colors = cy('bgrcmykbgrcmykbgrcmykbgrcmyk')
fori, each inzip(range(n_clusters_), colors):
my_members = labels == i
cluster_center = c_centers(k) plot(x_train(my_members, 0), x_train(my_members, 1), each + '.')
plot(cluster_center(0), cluster_center(1),
'o', markerfacecolor=each,
markeredgecolor='k', markersize=14)
title('Estimated cluster numbers: %d'% n_clusters_)
show()
L'extrait ci-dessus effectue un clustering et l'algorithme a trouvé des clusters centrés sur chaque blob que nous avons généré. Nous pouvons voir qu'à partir de l'image ci-dessous tracée par l'extrait de code, l'algorithme de décalage moyen est capable d'identifier le nombre de clusters nécessaires au moment de l'exécution et de déterminer la bande passante appropriée pour représenter la longueur d'interaction.
Production:
Exemple # 2
Basé sur la segmentation d'image en vision par ordinateur. Le deuxième extrait explorera comment l'algorithme de décalage moyen utilisé en apprentissage profond pour effectuer la segmentation de l'image colorée. Nous utilisons l'algorithme de décalage moyen pour identifier les clusters spatiaux. L'extrait précédent, nous avons utilisé un ensemble de données 2D alors que dans cet exemple, nous explorerons l'espace 3D. Le pixel de l'image sera traité comme des points de données (r, g, b). Nous devons convertir l'image au format tableau afin que chaque pixel représente le point de données dans l'image que nous allons au segment. Le regroupement des valeurs de couleur dans l'espace renvoie une série de clusters, où les pixels du cluster seront similaires à l'espace RVB. Packages utilisés pour implémenter l'algorithme Mean Shift:
Code:
importnumpy as np
fromcluster importMeanShift, estimate_bandwidth
fromdatasets.samples_generator importmake_blobs
importpyplot as plt
fromitertools import cycle
fromPIL import Image
Sous l'extrait de code pour effectuer la segmentation de l'image d'origine:
#Segmentation of Color Image
img = Image.open('Sample.jpg.webp')
img = np.array(img)
#Need to convert image into feature array based
flatten_img=np.reshape(img, (-1, 3))
#bandwidth estimation
est_bandwidth = estimate_bandwidth(flatten_img,
quantile=.2, n_samples=500)
mean_shift = MeanShift(est_bandwidth, bin_seeding=True)
fit(flatten_img)
labels= mean_shift.labels_
# Plot image vs segmented image
figure(2)
subplot(1, 1, 1)
imshow(img)
axis('off')
subplot(1, 1, 2)
imshow(np.reshape(labels, (854, 1224)))
axis('off')
L'image générée indique que cette approche pour identifier les formes d'images et déterminer les clusters spatiaux peut être effectuée efficacement sans aucun traitement d'image.
Production:


Avantages et applications Mean Shift Algorithm
Voici les avantages et l'application de l'algorithme moyen:
- Il est largement utilisé pour résoudre la vision par ordinateur, où il est utilisé pour la segmentation d'images.
- Clustering des points de données en temps réel sans mentionner le nombre de clusters.
- Fonctionne bien sur la segmentation d'image et le suivi vidéo.
- Plus robuste pour les valeurs aberrantes.
Avantages de l'algorithme de décalage moyen
Voici l'algorithme de décalage moyen des pros:
- La sortie de l'algorithme est indépendante des initialisations.
- La procédure est efficace car elle n'a qu'un seul paramètre - Bande passante.
- Aucune hypothèse sur le nombre de clusters de données et la forme.
- Il a de meilleures performances que le clustering K-Means.
Inconvénients de l'algorithme de décalage moyen
Voici les inconvénients de l'algorithme de décalage moyen:
- Cher pour les grandes fonctionnalités.
- Comparé au clustering K-Means, il est très lent.
- La sortie de l'algorithme dépend de la bande passante du paramètre.
- La sortie dépend de la taille de la fenêtre.
Conclusion
Bien qu'il s'agisse d'une approche simple qui principalement utilisé pour résoudre les problèmes liés à la segmentation de l'image, le clustering. Il est comparativement plus lent que K-Means et il est coûteux en calcul.
Articles recommandés
Ceci est un guide de l'algorithme de décalage moyen. Nous discutons ici des problèmes liés à la segmentation des images, au clustering, aux avantages et aux deux fonctions du noyau. Vous pouvez également consulter nos autres articles connexes pour en savoir plus-
- K- signifie algorithme de clustering
- Algorithme KNN dans R
- Qu'est-ce que l'algorithme génétique?
- Méthodes du noyau
- Méthodes du noyau dans l'apprentissage automatique
- Explication détaillée de l'algorithme C ++