

Introduction aux méthodes d'exploration de données
Les données augmentent quotidiennement à une échelle énorme. Mais toutes les données collectées ou collectées ne sont pas utiles. Les données significatives doivent être séparées des données bruyantes (données sans signification). Ce processus de séparation se fait par exploration de données.
Qu'est-ce que l'exploration de données?
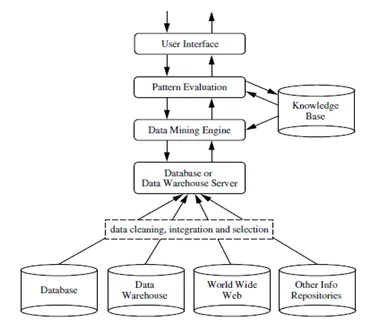
L'exploration de données est un processus d'extraction d'informations ou de connaissances utiles à partir d'une énorme quantité de données (ou big data). L'écart entre les données et les informations a été réduit en utilisant divers outils d'exploration de données. L'exploration de données peut également être appelée découverte de connaissances à partir de données ou KDD .
Sources: - www.ques10.com
L'exploration de données peut être effectuée sur différents types de bases de données et référentiels d'informations comme les bases de données relationnelles, les entrepôts de données, les bases de données transactionnelles, les flux de données et bien d'autres.
Différentes méthodes d'exploration de données:
Il existe de nombreuses méthodes utilisées pour l'exploration de données, mais l'étape cruciale consiste à sélectionner la méthode appropriée en fonction de l'entreprise ou de l'énoncé du problème. Ces méthodes d'exploration de données aident à prédire l'avenir, puis à prendre des décisions en conséquence. Ceux-ci aident également à analyser la tendance du marché et à augmenter les revenus de l'entreprise.
Certaines méthodes d'exploration de données sont les suivantes:
- Association
- Classification
- Analyse de clustering
- Prédiction
- Motifs séquentiels ou suivi de motifs
- Arbres de décision
- Analyse des valeurs aberrantes ou analyse des anomalies
- Réseau neuronal
Comprenons toutes les méthodes d'exploration de données une par une.
1. Association:
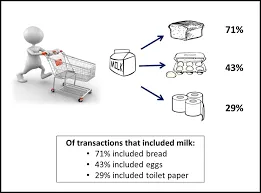
Il s'agit d'une méthode utilisée pour trouver une corrélation entre deux ou plusieurs éléments en identifiant le modèle caché dans l'ensemble de données et donc également appelée analyse de relation . Cette méthode est utilisée dans l'analyse du panier de consommation pour prédire le comportement du client.
Supposons que le responsable marketing d'un supermarché veuille déterminer quels produits sont fréquemment achetés ensemble.
Par exemple,
Achats (x, "bière") -> achats (x, "chips") (support = 1%, confiance = 50%)
- Ici, x représente un client achetant de la bière et des frites ensemble.
- La confiance montre que si un client achète une bière, il y a 50% de chances qu'il achète également les chips.
- Le soutien signifie que 1% de toutes les transactions analysées ont montré que la bière et les frites étaient achetées ensemble.
De nombreux exemples similaires comme du pain et du beurre ou des ordinateurs et des logiciels peuvent être envisagés.
Il existe deux types de règles d'association:
- Règle d'association unidimensionnelle: ces règles contiennent un seul attribut qui est répété.
- Règle d'association multidimensionnelle: ces règles contiennent plusieurs attributs qui sont répétés.
https://bit.ly/2N61gzR
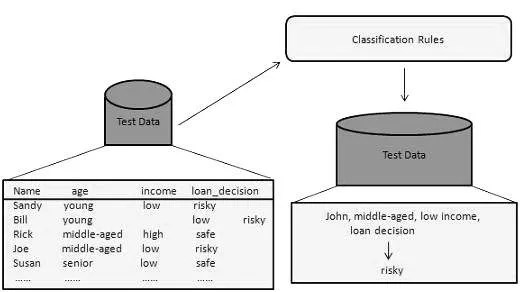
2. Classification:
Cette méthode d'exploration de données est utilisée pour distinguer les éléments des ensembles de données en classes ou en groupes. Il permet de prédire avec précision le comportement des éléments au sein du groupe. Il s'agit d'un processus en deux étapes:
- Étape d'apprentissage (phase de formation): dans ce cas, un algorithme de classification construit le classificateur en analysant un ensemble de formation.
- Étape de classification: Les données de test sont utilisées pour estimer l'exactitude ou la précision des règles de classification.
Par exemple, une entreprise bancaire utilise pour identifier les demandeurs de prêts présentant des risques de crédit faibles, moyens ou élevés. De même, un chercheur médical analyse les données sur le cancer pour prédire quel médicament prescrire au patient.
Sources: - www.tutorialspoint.com
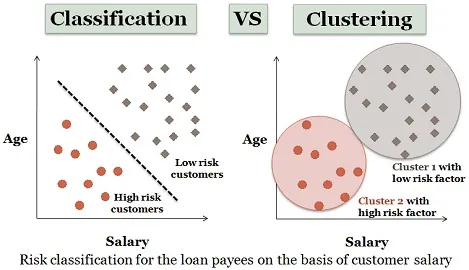
3. Analyse de regroupement:
Le regroupement est presque similaire à la classification, mais dans ce cas, les regroupements sont effectués en fonction des similitudes des éléments de données. Différents clusters ont des objets différents ou sans rapport. Il est également appelé segmentation des données car il partitionne d'énormes ensembles de données en grappes en fonction des similitudes.
Il existe différentes méthodes de clustering qui sont utilisées:
- Méthodes d'agglomération hiérarchique
- Méthodes basées sur une grille
- Méthodes de partitionnement
- Méthodes basées sur un modèle
- Méthodes basées sur la densité
Un exemple similaire de demandeurs de prêt peut également être considéré ici. Certaines différences sont illustrées dans la figure ci-dessous.
https://bit.ly/2N6aZpP
4. Prédiction:
Cette méthode est utilisée pour prédire l'avenir en fonction des tendances passées et présentes ou de l'ensemble de données. La prédiction est principalement utilisée avec la combinaison d'autres méthodes d'exploration de données telles que la classification, l'appariement de motifs, l'analyse des tendances et les relations.
Par exemple, si le directeur des ventes d'un supermarché souhaite prédire le montant des revenus que chaque article générerait sur la base des données de ventes passées. Il modélise une fonction à valeur continue qui prédit les valeurs de données numériques manquantes.

Sources: - data-mining.philippe-fournier
L'analyse de régression est le meilleur choix pour effectuer une prédiction. Il peut être utilisé pour définir une relation entre des variables indépendantes et des variables dépendantes.
5. Modèles séquentiels ou suivi des modèles:
Cette méthode d'exploration de données est utilisée pour identifier les modèles qui se produisent fréquemment sur une certaine période de temps.
Par exemple, le directeur des ventes de la société de vêtements constate que les ventes de vestes semblent augmenter juste avant la saison d'hiver, ou que les ventes dans les boulangeries augmentent à Noël ou au Nouvel An.
Regardons un exemple avec un graphique
Sources: - data-mining.philippe-fournier-viger
6.Arbres de décision:
Un arbre de décision est une structure arborescente (comme son nom l'indique), où
- Chaque nœud interne représente un test sur l'attribut.
- La branche indique le résultat du test.
- Les nœuds terminaux contiennent l'étiquette de classe.
- Le nœud le plus haut est le nœud racine qui a la question simple qui a deux ou plusieurs réponses. Par conséquent, l'arbre grandit et une structure semblable à un organigramme est générée.
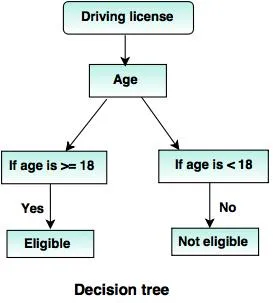
Sources: - www.tutorialride.com
Dans cette décision, le gouvernement de l'arbre classe les citoyens de moins de 18 ans ou de plus de 18 ans. Cela les aiderait à décider si un permis doit être délivré à un citoyen particulier ou non.
7. analyse antérieure ou analyse d'anomalie:
Cette méthode d'exploration de données est utilisée pour identifier les éléments de données qui ne sont pas conformes au modèle ou au comportement attendu. Ces éléments de données inattendus sont considérés comme des valeurs aberrantes ou du bruit. Ils sont utiles dans de nombreux domaines tels que la détection de fraude par carte de crédit, la détection d'intrusion, la détection de pannes, etc.
Par exemple, supposons que le graphique ci-dessous est tracé à l'aide de certains ensembles de données dans notre base de données.
La ligne la mieux ajustée est donc tracée. Les points situés à proximité de la ligne montrent le comportement attendu tandis que le point éloigné de la ligne est une valeur aberrante.
Cela aiderait à détecter les anomalies et à prendre les mesures possibles en conséquence.
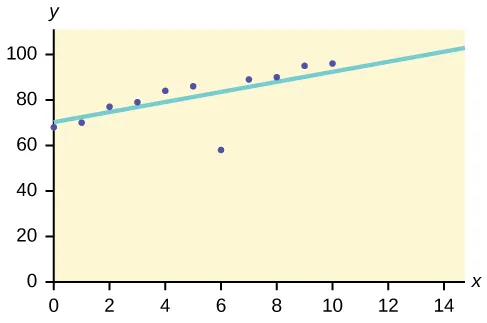
https://bit.ly/2GrgjDP
8. Réseau de neurones:
Cette méthode ou modèle d'exploration de données est basée sur des réseaux neuronaux biologiques. C'est une collection de neurones comme des unités de traitement avec des connexions pondérées entre eux. Ils sont utilisés pour modéliser la relation entre les entrées et les sorties. Il est utilisé pour la classification, l'analyse de régression, le traitement des données, etc. Cette technique fonctionne sur trois piliers:
- Modèle
- Algorithme d'apprentissage (supervisé ou non supervisé)
- Fonction d'activation
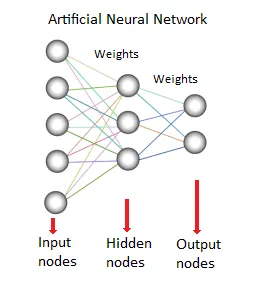
Sources: - www.saedsayad.com
Articles recommandés
Cela a été un guide pour les méthodes d'exploration de données Ici, nous avons discuté de ce qu'est l'exploration de données et des différents types de méthode d'exploration de données avec l'exemple. Vous pouvez également consulter les articles suivants pour en savoir plus -
- Logiciel d'analyse de Big Data
- Questions d'entretiens chez Data Structure
- Techniques importantes d'exploration de données
- Architecture d'exploration de données