

Introduction aux commandes Hive
La commande Hive est un outil d'infrastructure d'entrepôt de données qui se trouve sur Hadoop pour résumer les Big Data. Il traite des données structurées. Il facilite l'interrogation et l'analyse des données. La commande Hive est également appelée «schéma à la lecture». Hive ne vérifie pas les données lorsqu'elles sont chargées, la vérification ne se produit que lorsqu'une requête est émise. Cette propriété de Hive le rend rapide pour le chargement initial. C'est comme copier ou simplement déplacer un fichier sans mettre de contraintes ou de contrôles. La ruche a d'abord été développée par Facebook. Apache Software Foundation l'a repris plus tard et l'a développé davantage.
Voici les composants de la commande Hive:
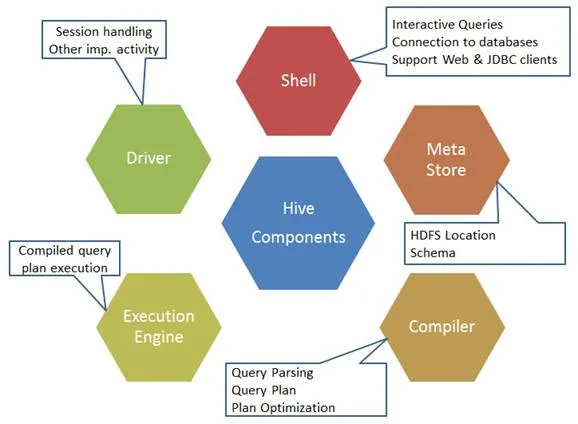
Fig 1. Composants de la ruche
https://www.developer.com/
Voici les fonctionnalités de la commande Hive répertoriées ci-dessous:
- Les magasins Hive sont des jeux de données bruts et traités dans Hadoop.
- Il est conçu pour le traitement des transactions en ligne (OLTP). OLTP est le système qui facilite les volumes de données élevés en très peu de temps sans avoir recours à un seul serveur.
- Il est rapide, évolutif et fiable.
- Le langage d'interrogation de type SQL fourni ici est appelé HiveQL ou HQL. Cela facilite les tâches ETL et autres analyses.
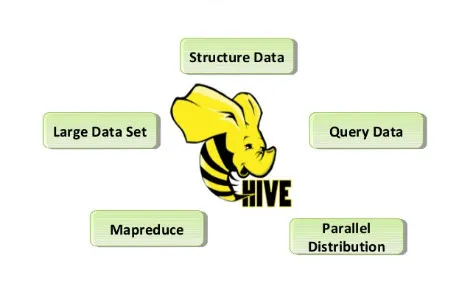
Fig 2. Propriétés de la ruche
Images sources: - Google
Il existe également quelques limitations de la commande Hive, qui sont répertoriées ci-dessous:
- Hive ne prend pas en charge les sous-requêtes.
- Hive prend sûrement en charge l'écrasement, mais malheureusement, il ne prend pas en charge la suppression et les mises à jour.
- Hive n'est pas conçu pour OLTP, mais il est utilisé pour cela.
Pour entrer dans le shell interactif de la ruche:
$ HIVE_HOME / bin / hive
Commandes de base de la ruche
-
Créer
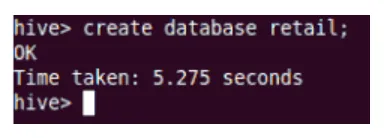
Cela créera la nouvelle base de données dans Hive.
-
Laissez tomber
La goutte supprimera une table de Hive
-
Modifier
La commande de modification vous aidera à renommer la table ou les colonnes de table.
Par exemple:
ruche> ALTER TABLE employé RENAME TO employé1;
-
Spectacle
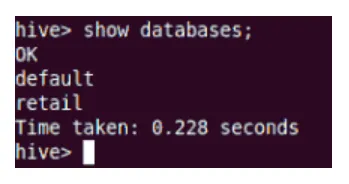
La commande Show affichera toutes les bases de données résidant dans Hive.
-
Décris
La commande Décrire vous aidera avec les informations sur le schéma de la table.
Commandes de ruche intermédiaires
Hive divise une table en différentes partitions liées basées sur des colonnes. En utilisant ces partitions, il est plus facile d'interroger des données. Ces partitions sont ensuite divisées en compartiments pour exécuter efficacement les requêtes sur les données.
En d'autres termes, les compartiments distribuent des données dans l'ensemble de clusters en calculant le code de hachage de la clé mentionné dans la requête.
-
Ajout d'une partition
L'ajout d'une partition peut être accompli en modifiant la table. Supposons que vous ayez la table «EMP», avec des champs tels que Id, Nom, Salaire, Dept, Désignation et yoj.
ruche> employé ALTER TABLE
> AJOUTER UNE PARTITION (année = '2012')
emplacement '/ 2012 / part2012';
-
Renommer la partition
ruche> ALTER TABLE employé PARTITION (année = '1203')
RENOMMER EN PARTITION (Yoj = '1203');
-
Supprimer la partition
ruche> ALTER TABLE employé DROP (SI EXISTE)
> PARTITION (année = '1203');
-
Opérateurs relationnels
Les opérateurs relationnels se composent d'un certain ensemble d'opérateurs, ce qui aide à récupérer les informations pertinentes.
Par exemple: dites que votre table «EMP» ressemble à ceci:
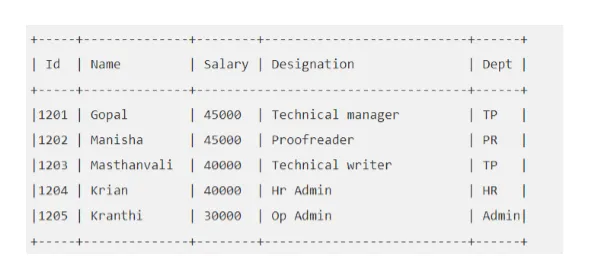
Exécutons la requête Hive qui va nous chercher l'employé dont le salaire est supérieur à 30000.
ruche> SELECT * FROM EMP WHERE Salary> = 40000;
-
Opérateurs arithmétiques
Ce sont des opérateurs qui aident à exécuter des opérations arithmétiques sur les opérandes et, à leur tour, renvoient toujours des types de nombres.
Par exemple: pour ajouter deux nombres tels que 22 et 33
ruche> SELECT 22 + 33 ADD FROM temp;
-
Opérateur logique
Ces opérateurs doivent exécuter des opérations logiques qui, en retour, renvoient toujours True / False.
ruche> SÉLECTIONNER * DE L'EMP OMP Salaire> 40000 && Dept = TP;
Commandes avancées de ruche
-
Vue
Le concept de vue dans Hive est similaire à celui de SQL. La vue peut être créée au moment de l'exécution d'une instruction SELECT.
Exemple:
ruche> CRÉER UNE VUE EMP_30000 AS
CHOISIR * À PARTIR D'EMP
O salary salaire> 30000;
-
Chargement des données dans le tableau
Hive> Charger les données du chemin local '/home/hduser/Desktop/AllStates.csv' dans les états de la table;
Ici, «States» est le tableau déjà créé dans Hive.
https://www.tutorialspoint.com/hive/
Hive possède des fonctions intégrées qui vous aident à récupérer votre résultat de manière plus efficace.
Comme rond, sol, BIGINT etc.
-
Joindre
La clause Join peut aider à joindre deux tables basées sur le même nom de colonne.
Exemple:
ruche> SELECT c.ID, c.NAME, c.AGE, o.AMOUNT
DES CLIENTS c REJOINDRE LES COMMANDES o
ON (c.ID = o.CUSTOMER_ID);
Tous les types de jointures sont pris en charge par Hive: jointure externe gauche, jointure externe droite, jointure externe complète.
Trucs et astuces pour utiliser les commandes de la ruche
Hive rend le traitement des données aussi simple, simple et extensible que l'utilisateur accorde moins d'attention à l'optimisation des requêtes Hive. Mais faire attention à peu de choses lors de l'écriture de la requête Hive apportera certainement un grand succès dans la gestion de la charge de travail et des économies d'argent. Voici quelques conseils à ce sujet:
- Partitions et compartiments: Hive est un outil de Big Data, qui peut interroger de grands ensembles de données. Cependant, écrire la requête sans comprendre le domaine peut apporter de grandes partitions dans Hive.
Si l'utilisateur connaît l'ensemble de données, les colonnes pertinentes et très utilisées peuvent être regroupées dans la même partition. Cela vous aidera à exécuter la requête plus rapidement et de manière inefficace.
En fin de compte, le non. des opérations de mappage et d'E / S seront également réduites.
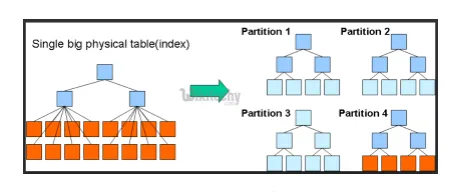
Fig 3. Partitionnement
Images sources: image Google
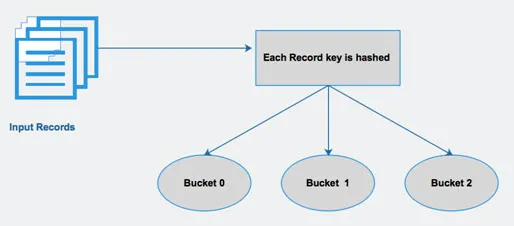
Fig 4 Bucketing
Images sources: - Image Google
- Exécution parallèle: Hive exécute la requête en plusieurs étapes. Dans certains cas, ces étapes peuvent dépendre d'autres étapes et ne peuvent donc pas démarrer une fois l'étape précédente terminée. Cependant, des tâches indépendantes peuvent s'exécuter en parallèle pour économiser le temps d'exécution global. Pour activer l'exécution parallèle dans Hive:
définissez hive.exec.parallel = true;
Par conséquent, cela améliorera l'utilisation du cluster.
- Échantillonnage en bloc: l' échantillonnage des données d'une table permettra d'explorer les requêtes sur les données.
Malgré le tronçonnage, nous voulons plutôt échantillonner l'ensemble de données de manière plus aléatoire. L'échantillonnage par blocs est fourni avec diverses syntaxes puissantes, qui aident à échantillonner les données de différentes manières.
L'échantillonnage peut être utilisé pour trouver env. des informations provenant d'un ensemble de données comme la distance moyenne entre l'origine et la destination.
Interroger 1% des mégadonnées donnera presque la réponse parfaite. L'exploration devient beaucoup plus facile et efficace.
Conclusion - Commandes Hive
Hive est une abstraction de niveau supérieur au-dessus de HDFS, qui fournit un langage de requête flexible. Il aide à interroger et à traiter les données de manière plus simple.
Hive peut être associé à d'autres éléments Big Data pour exploiter pleinement ses fonctionnalités.
Articles recommandés
Cela a été un guide pour les commandes Hive. Ici, nous avons discuté des commandes Hive de base et avancées et de certaines commandes Hive immédiates. Vous pouvez également consulter l'article suivant pour en savoir plus -
- Questions d'entretiens chez Hive
- Hive VS Hue - Top 6 des comparaisons utiles
- Commandes Tableau
- Commandes Adobe Photoshop
- Utilisation de la fonction ORDER BY dans Hive
- Téléchargez et installez Hive étape par étape