

Introduction à Map Join dans Hive
La jointure de carte est une fonctionnalité utilisée dans les requêtes Hive pour augmenter son efficacité en termes de vitesse. La jointure est une condition utilisée pour combiner les données de 2 tables. Ainsi, lorsque nous effectuons une jointure normale, le travail est envoyé à une tâche Map-Reduce qui divise la tâche principale en 2 étapes - «Map stage» et «Reduce stage». L'étape Map interprète les données d'entrée et renvoie la sortie à l'étape de réduction sous la forme de paires clé-valeur. Cela passe ensuite par l'étape de mélange où ils sont triés et combinés. Le réducteur prend cette valeur triée et termine le travail de jointure.
Une table peut être chargée dans la mémoire complètement dans un mappeur et sans avoir à utiliser le processus Map / Reducer. Il lit les données de la petite table et les stocke dans une table de hachage en mémoire, puis les sérialise dans un fichier de mémoire de hachage, ce qui réduit considérablement le temps. Il est également connu sous le nom de Map Side Join in Hive. Fondamentalement, cela implique d'effectuer des jointures entre 2 tables en utilisant uniquement la phase de carte et en ignorant la phase de réduction. Une diminution du temps dans le calcul de vos requêtes peut être observée si elles utilisent régulièrement une petite table jointe.
Syntaxe de Map Join dans Hive
Si nous voulons effectuer une requête de jointure en utilisant map-join, nous devons spécifier un mot clé "/ * + MAPJOIN (b) * /" dans la déclaration comme ci-dessous:
>SELECT /*+ MAPJOIN(c) */ * FROM tablename1 t1 JOIN tablename2 t2 ON (t1.emp_id = t2.emp_id);
Pour cet exemple, nous devons créer 2 tables avec les noms tablename1 et tablename2 ayant 2 colonnes: emp_id et emp_name. L'un doit être un fichier plus grand et l'autre doit être plus petit.
Avant d'exécuter la requête, nous devons définir la propriété ci-dessous sur true:
hive.auto.convert.join=true
La requête de jointure pour la jointure de carte est écrite comme ci-dessus et le résultat que nous obtenons est:
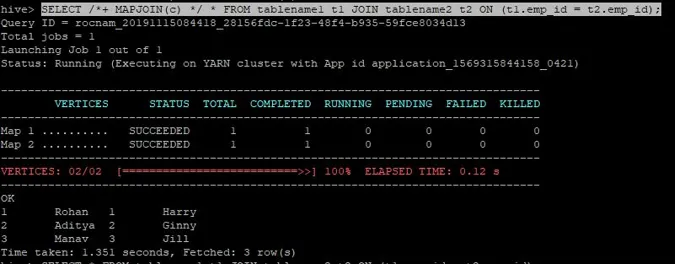
La requête s'est terminée en 1, 351 secondes.
Exemples de jonction de carte dans la ruche
Voici les exemples suivants mentionnés ci-dessous
1. Exemple de jointure de carte
Pour cet exemple, créons 2 tables nommées table1 et table2 avec 100 et 200 enregistrements respectivement. Vous pouvez vous référer à la commande ci-dessous et aux captures d'écran pour les exécuter:
>CREATE TABLE IF NOT EXISTS table1 ( emp_id int, emp_name String, email_id String, gender String, ip_address String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");
>CREATE TABLE IF NOT EXISTS table2 ( emp_id int, emp_name String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");

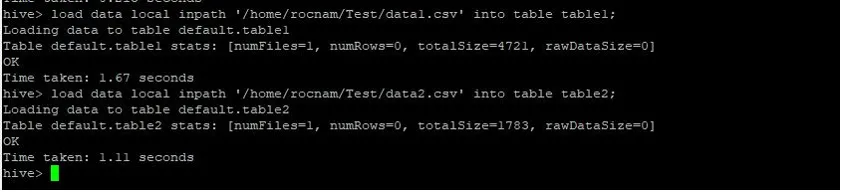
Maintenant, nous chargeons les enregistrements dans les deux tableaux à l'aide des commandes ci-dessous:
>load data local inpath '/relativePath/data1.csv' into table table1;
>load data local inpath '/relativePath/data2.csv' into table table2;
Laissez-nous effectuer une requête de jointure de carte normale sur leurs identifiants comme indiqué ci-dessous et vérifions le temps nécessaire pour les mêmes:
>SELECT /*+ MAPJOIN(table2) */ table1.emp_name, table1.emp_id, table2.emp_id FROM table1 JOIN table2 ON table1.emp_name = table2.emp_name;
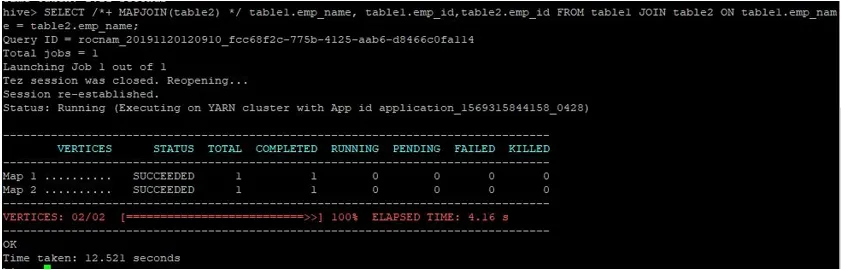
Comme nous pouvons le voir, une requête de jointure de carte normale a pris 12, 521 secondes.
2. Exemple de jointure Bucket-Map
Utilisons maintenant la jointure Bucket-map pour exécuter la même chose. Il y a quelques contraintes qui doivent être suivies pour le regroupement:
- Les compartiments ne peuvent être joints les uns aux autres que si le nombre total de compartiments d'une table est multiple du nombre de compartiments de l'autre table.
- Doit avoir des tables regroupées pour effectuer le regroupement. Créons donc la même chose.
Voici les commandes utilisées pour créer des tables regroupées table1 et table2:
>>CREATE TABLE IF NOT EXISTS table1_buk (emp_id int, emp_name String, email_id String, gender String, ip_address String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ';
>CREATE TABLE IF NOT EXISTS table2_buk ( emp_id int, emp_name String) clustered by(emp_name) into 8 buckets row format delimited fields terminated BY ', ' ;

Nous allons également insérer les mêmes enregistrements de table1 dans ces tableaux regroupés:
>insert into table1_buk select * from table1;
>insert into table2_buk select * from table2;
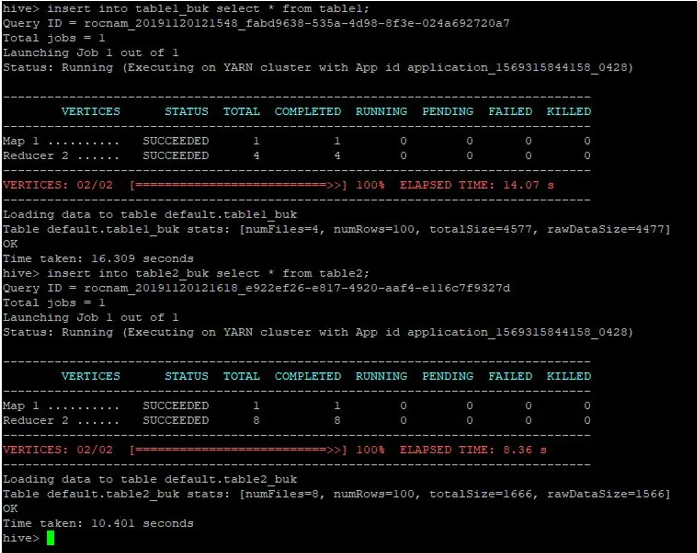
Maintenant que nous avons nos 2 tables regroupées, exécutons une jointure de carte de regroupement sur celles-ci. La première table a 4 compartiments tandis que la deuxième table a 8 compartiments créés sur la même colonne.
Pour que la requête de jointure bucket-map fonctionne, nous devons définir la propriété ci-dessous sur true dans la ruche:
set hive.optimize.bucketmapjoin = true
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
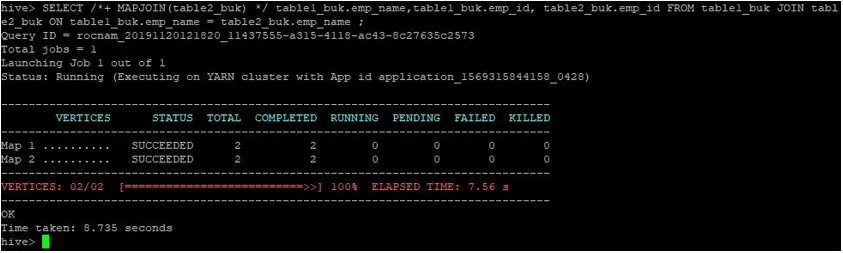
Comme nous pouvons le voir, la requête s'est terminée en 8, 735 secondes, ce qui est plus rapide qu'une jointure de carte normale.
3. Exemple de jointure de carte de regroupement de regroupements (SMB)
SMB peut être exécuté sur des tables regroupées ayant le même nombre de compartiments et si les tables doivent être triées et regroupées sur des colonnes de jointure. Le niveau du mappeur joint ces compartiments de manière correspondante.
Comme pour la jointure Bucket-map, il y a 4 compartiments pour table1 et 8 compartiments pour table2. Pour cet exemple, nous allons créer une autre table avec 4 godets.
Pour exécuter la requête SMB, nous devons définir les propriétés de ruche suivantes comme indiqué ci-dessous:
Hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
hive.optimize.bucketmapjoin = true;
hive.optimize.bucketmapjoin.sortedmerge = true;
Pour effectuer la jointure SMB, les données doivent être triées conformément aux colonnes de jointure. Par conséquent, nous remplaçons les données du tableau 1 regroupées comme suit:
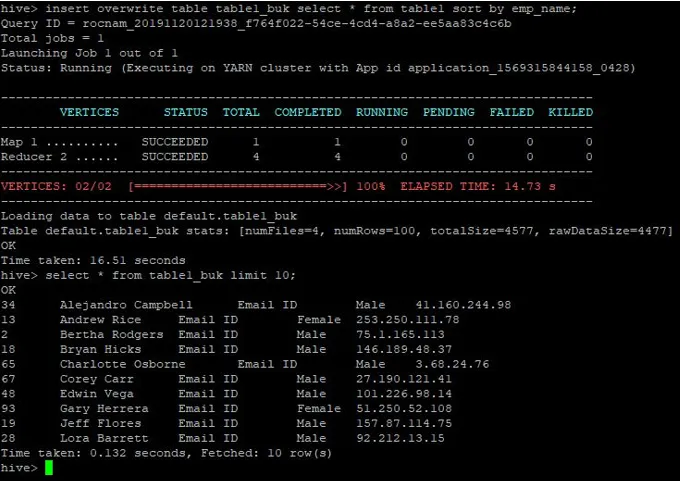
>insert overwrite table table1_buk select * from table1 sort by emp_name;
Les données sont maintenant triées, ce qui peut être vu dans la capture d'écran ci-dessous:
Nous remplacerons également les données dans le tableau compartimenté2 comme ci-dessous:
>insert overwrite table table2_buk select * from table2 sort by emp_name;

Laissez-nous effectuer la jointure pour les 2 tables ci-dessus comme suit:
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
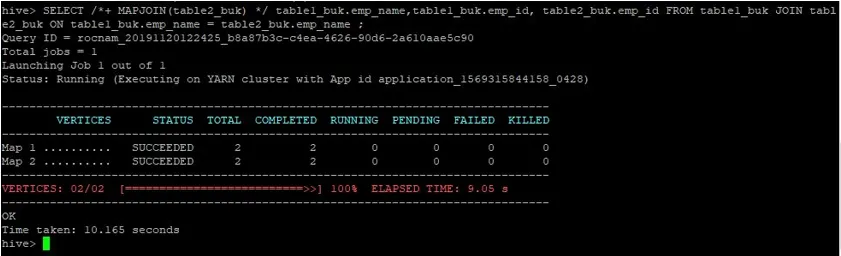
Nous pouvons voir que la requête a pris 10, 165 secondes, ce qui est encore mieux qu'une jointure de carte normale.
Créons maintenant une autre table pour table2 avec 4 compartiments et les mêmes données triées avec emp_name.
>CREATE TABLE IF NOT EXISTS table2_buk1 (emp_id int, emp_name String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ' ;
>insert overwrite table table2_buk1 select * from table2 sort by emp_name;
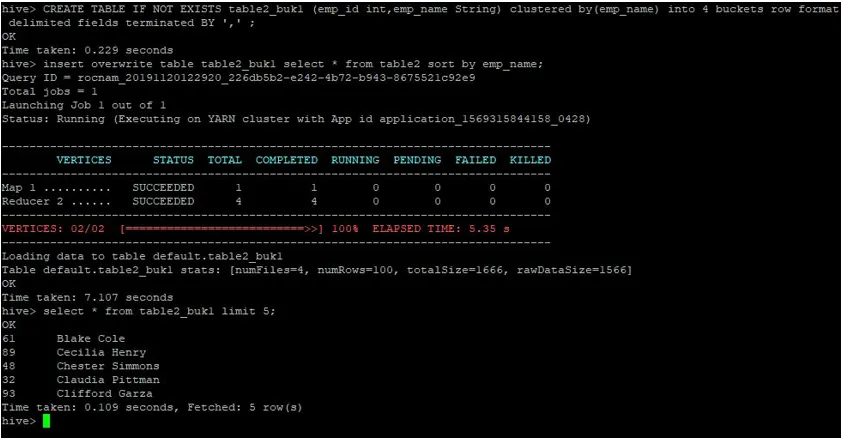
Étant donné que nous avons maintenant les deux tables avec 4 compartiments, exécutons à nouveau une requête de jointure.
>SELECT /*+ MAPJOIN(table2_buk1) */table1_buk.emp_name, table1_buk.emp_id, table2_buk1.emp_id FROM table1_buk JOIN table2_buk1 ON table1_buk.emp_name = table2_buk1.emp_name ;
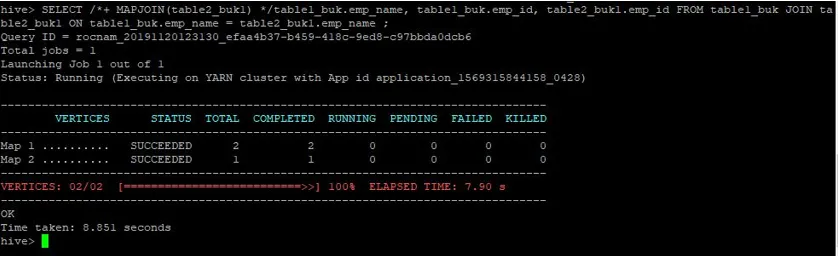
La requête a pris de nouveau 8, 851 secondes plus rapidement que la requête de jointure de carte normale.
Les avantages
- La jointure de carte réduit le temps nécessaire aux processus de tri et de fusion se déroulant dans le shuffle et réduit les étapes, minimisant ainsi le coût également.
- Il augmente l'efficacité des performances de la tâche.
Limites
- Le même tableau / alias n'est pas autorisé à être utilisé pour joindre différentes colonnes dans la même requête.
- La requête de jointure de carte ne peut pas convertir les jointures externes complètes en jointures latérales de carte.
- La jointure de carte ne peut être effectuée que lorsque l'une des tables est suffisamment petite pour être adaptée à la mémoire. Par conséquent, il ne peut pas être effectué lorsque les données de la table sont énormes.
- Une jointure gauche peut être effectuée sur une jointure de carte uniquement lorsque la taille de la table droite est petite.
- Une jointure droite peut être effectuée sur une jointure de carte uniquement lorsque la taille de la table gauche est petite.
Conclusion
Nous avons essayé d'inclure les meilleurs points possibles de Map Join dans Hive. Comme nous l'avons vu ci-dessus, la jointure côté carte fonctionne mieux lorsqu'une table contient moins de données afin que le travail soit terminé rapidement. Le temps nécessaire pour les requêtes affichées ici dépend de la taille de l'ensemble de données, par conséquent le temps affiché ici est uniquement pour l'analyse. La jointure de carte peut facilement être implémentée dans des applications en temps réel, car nous avons d'énormes données, contribuant ainsi à réduire le trafic d'E / S du réseau.
Articles recommandés
Ceci est un guide pour Map Join dans Hive. Nous discutons ici des exemples de Map Join in Hive ainsi que des avantages et limites. Vous pouvez également consulter l'article suivant pour en savoir plus -
- Se joint à Hive
- Fonctions intégrées de la ruche
- Qu'est-ce qu'une ruche?
- Commandes Hive