

Introduction aux commandes Pig
Apache Pig est un outil / plate-forme utilisé pour analyser de grands ensembles de données et effectuer de longues séries d'opérations sur les données. Pig est utilisé avec Hadoop. Tous les scripts pig sont convertis en interne en tâches de réduction de carte, puis exécutés. Il peut gérer des données structurées, semi-structurées et non structurées. Pig stocke son résultat en HDFS. Dans cet article, nous apprenons les autres types de commandes Pig.
Voici quelques caractéristiques de Pig:
- Auto-optimisation: Pig peut optimiser les tâches d'exécution, l'utilisateur a la liberté de se concentrer sur la sémantique.
- Facilité de programmation: Pig fournit un langage / dialecte de haut niveau appelé Pig Latin, qui est facile à écrire. Pig Latin fournit de nombreux opérateurs que le programmeur peut utiliser pour traiter les données. Le programmeur a également la possibilité d'écrire ses propres fonctions.
- Extensible: Pig facilite la création de fonctions personnalisées appelées UDF (fonctions définies par l'utilisateur), qui rendent les programmeurs capables de répondre à toutes les exigences de traitement rapidement et facilement. Le script Pig s'exécute sur un shell appelé grunt.
Pourquoi Pig Commands?
Les programmeurs qui ne maîtrisent pas Java ont généralement du mal à écrire des programmes dans Hadoop, c'est-à-dire à écrire des tâches de réduction de carte. Pour eux, Pig Latin, qui ressemble beaucoup au langage SQL, est une aubaine. Son approche multi-requêtes réduit la longueur du code.
Donc, dans l'ensemble, sa façon concise et efficace de programmation. Les commandes Pig peuvent invoquer du code dans de nombreux langages comme JRuby, Jython et Java.
L'architecture des commandes Pig
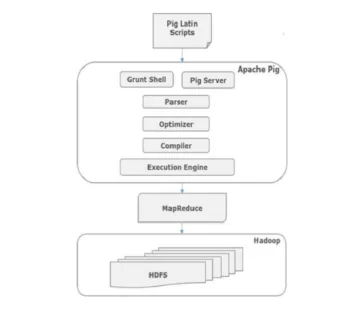
Tous les scripts écrits en Pig-Latin sur le shell grunt vont à l'analyseur pour vérifier la syntaxe et d'autres vérifications diverses se produisent également. La sortie de l'analyseur est un DAG. Ce DAG est ensuite transmis à l'Optimizer, qui effectue ensuite une optimisation logique telle que la projection et pousse vers le bas. Ensuite, le compilateur conforme le plan logique aux travaux MapReduce. Enfin, ces travaux MapReduce sont soumis à Hadoop dans l'ordre trié. Ces travaux sont exécutés et produisent les résultats souhaités.
Le modèle de données Pig-Latin est entièrement imbriqué et permet des types de données complexes tels que la carte et le tuple.
Toute valeur unique de la langue latine Pig (quel que soit le type de données) est appelée Atom.
Commandes de base du cochon
Jetons un coup d'œil à certaines des commandes de base de Pig qui sont données ci-dessous: -
1. Fs: Ceci listera tous les fichiers du HDFS
grognement> fs –ls
2. Clear: Cela effacera le shell Grunt interactif.
grognement> clair
3. Histoire:
Cette commande affiche les commandes exécutées jusqu'à présent.
grognement> histoire
4. Lecture des données: en supposant que les données résident dans HDFS, et nous devons lire les données dans Pig.
grunt> college_students = LOAD 'hdfs: // localhost: 9000 / pig_data / college_data.txt'
UTILISATION de PigStorage (', ')
as (id: int, prénom: chararray, nom: chararray, téléphone: chararray,
ville: chararray);
PigStorage () est la fonction qui charge et stocke les données sous forme de fichiers texte structurés.
5. Stockage des données: l'opérateur de stockage est utilisé pour stocker les données traitées / chargées.
grunt> STORE college_students INTO 'hdfs: // localhost: 9000 / pig_Output /' USING PigStorage (', ');
Ici, "/ pig_Output /" est le répertoire où la relation doit être stockée.
6. Opérateur de vidage: cette commande est utilisée pour afficher les résultats à l'écran. Cela aide généralement au débogage.
grogner> Dump college_students;
7. Décrire l'opérateur: il aide le programmeur à visualiser le schéma de la relation.
grogner> décrire college_students;
8. Expliquez: Cette commande permet de revoir les plans d'exécution logique, physique et de réduction de carte.
grogner> expliquer college_students;
9. Opérateur Illustrate: il donne l'exécution pas à pas des instructions dans les commandes Pig.
grogner> illustrer college_students;
Commandes intermédiaires de porc
1. Grouper: cette commande Pig fonctionne pour regrouper les données avec la même clé.
grunt> group_data = GROUP college_students par prénom;
2. COGROUP: Il fonctionne de manière similaire à l'opérateur de groupe. La principale différence entre l'opérateur Group & Cogroup est que l'opérateur de groupe est généralement utilisé avec une relation, tandis que cogroup est utilisé avec plusieurs relations.
3. Join: Ceci est utilisé pour combiner deux ou plusieurs relations.
Exemple: Pour effectuer une auto-jointure, disons que la relation «client» est chargée à partir des commandes HDFS tp pig dans deux relations clients1 et clients2.
grognement> clients3 = REJOINDRE clients1 BY id, clients2 BY id;
La jointure peut être auto-jointe, jointure interne, jointure externe.
4. Cross: cette commande pig calcule le produit croisé de deux ou plusieurs relations.
grunt> cross_data = CROSS clients, commandes;
5. Union: elle fusionne deux relations. La condition de fusion est que les colonnes et les domaines de la relation doivent être identiques.
grognement> étudiant = UNION étudiant1, étudiant2;
Commandes avancées de cochon
Jetons un coup d'œil à certaines des commandes avancées de Pig qui sont données ci-dessous:
1. Filtre: Cela aide à filtrer les tuples hors de relation, en fonction de certaines conditions.
filter_data = FILTER college_students BY city == 'Chennai';
2. Distinct: Cela aide à supprimer les tuples redondants de la relation.
grunt> distinct_data = DISTINCT college_students;
Ce filtrage créera un nouveau nom de relation "distinct_data"
3. Foreach: cela aide à générer une transformation de données basée sur des données de colonne.
grunt> foreach_data = FOREACH student_details GÉNÉRER id, âge, ville;
Cela obtiendra l'id, l'âge et les valeurs de ville de chaque élève de la relation student_details et donc les stockera dans une autre relation nommée foreach_data.
4. Trier par: cette commande affiche le résultat dans un ordre trié basé sur un ou plusieurs champs.
grunt> order_by_data = ORDER college_students BY age DESC;
Cela triera la relation «college_students» par ordre décroissant par âge.
5. Limite: Cette commande obtient un nombre limité. de tuples de la relation.
grunt> limit_data = LIMIT student_details 4;
Trucs et astuces
Voici les différents trucs et astuces des commandes Pig: -
1. Activez la compression sur vos entrées et sorties:
définissez input.compression.enabled true;
définissez output.compression.enabled true;
Les lignes de code mentionnées ci-dessus doivent être au début du script, ce qui permettra aux commandes Pig de lire les fichiers compressés ou de générer des fichiers compressés en sortie.
2. Rejoignez plusieurs relations:
Pour effectuer la jointure gauche sur, disons, trois relations (entrée1, entrée2, entrée3), il faut opter pour SQL. C'est parce que la jointure externe n'est pas prise en charge par Pig sur plus de deux tables.
Au contraire, vous effectuez à gauche pour rejoindre en deux étapes comme:
data1 = JOIN entrée1 BY clé GAUCHE, entrée2 BY clé;
data2 = JOIN data1 BY input1 :: key LEFT, input3 BY key;
Cela signifie deux tâches de réduction de carte.
Pour effectuer la tâche ci-dessus plus efficacement, on peut opter pour «Cogroup». Cogroup peut rejoindre plusieurs relations. Cogroup par défaut fait la jointure externe.
Conclusion
Pig est un langage procédural, généralement utilisé par les scientifiques des données pour effectuer un traitement ad hoc et un prototypage rapide. C'est un excellent ETL et un outil de traitement de données volumineux. Les scripts Pig peuvent être invoqués par d'autres langages et vice versa. Par conséquent, les commandes Pig peuvent être utilisées pour créer des applications plus grandes et complexes.
Articles recommandés
Cela a été un guide pour les commandes Pig. Ici, nous avons discuté des commandes Pig de base et avancées et de certaines commandes Pig immédiates. Vous pouvez également consulter l'article suivant pour en savoir plus -
- Commandes Adobe Photoshop
- Commandes Tableau
- Aide-mémoire SQL (commandes, conseils gratuits et astuces)
- Commandes VBA - Touches de finition
- Différentes opérations liées aux tuples