

Introduction à l'installation de la ruche
Dans l'installation Hive, certaines conditions préalables doivent être remplies avant l'installation.
Les composants Hadoop comme Hive, Hbase, Pig, etc. prennent tous en charge l'environnement Linux. Par conséquent, il est recommandé d'avoir un système d'exploitation Linux sur votre appareil. Si ce n'est pas le cas et que vous souhaitez vous entraîner sur la ruche tout en ayant des fenêtres sur votre système. Ce que vous pouvez faire est d'installer la machine CDH sur votre système et de l'utiliser comme plate-forme pour explorer Hadoop. Cela nécessitera un minimum de 4 Go de RAM sur votre système ou vous pouvez avoir une machine CDH dans votre clé USB et l'utiliser.
Quoi qu'il en soit, vous pouvez toujours avoir une solution à votre question, peut-être plus tôt que tard.
Prérequis pour installer Hive
Il existe certaines conditions préalables pour installer la ruche sur n'importe quelle machine:
- Installation Java
- Installation de Hadoop
Étape 1
- Vérifiez que Java est installé.
- Ouvrez le terminal et tapez la commande.
Version Java
- Si java est installé sur le système, il vous donnera la version ou bien une erreur. Dans mon cas, Java est déjà installé et ci-dessous est la sortie de la commande.

- Dans le cas, Java n'est pas installé sur votre système. Vous pouvez visiter le lien ci-dessous et télécharger java et l'installer.
- http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads- 1880260.html.
Installation Java
- Extraire le téléchargé.
- Déplacez-le dans «/ usr / local /».
- Configurez les variables PATH et JAVA_HOME.
Étape 2
- Vérifiez que Hadoop est installé.
- Ouvrez le terminal et tapez la commande.
Version Hadoop
- Si Hadoop est déjà installé, cette commande vous donnera la version ou bien une erreur.
- Dans mon cas, Hadoop a déjà installé d'où la sortie ci-dessous.
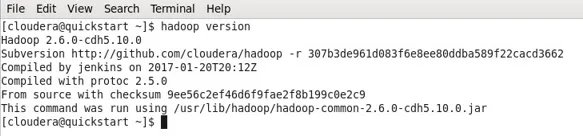
- Vous pouvez maintenant observer que je travaille avec une machine CDH5.
- Si Hadoop n'est pas installé, téléchargez la fondation logicielle Hadoop depuis Apache.
Installation de Hadoop
1. Configurer Hadoop
2. Configurer Hadoop
Les fichiers à modifier pour configurer Hadoop sont:
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
3. Configurez Namenode à l'aide de la commande:
Hdfs namenode -format
4. Démarrez dfs à l'aide de la commande suivante:
start -dfs.sh
5. Démarrez le fil à l'aide de la commande:
Start -yarn.sh
Comment installer Hive?
Ci-dessous les points aident à installer la ruche:
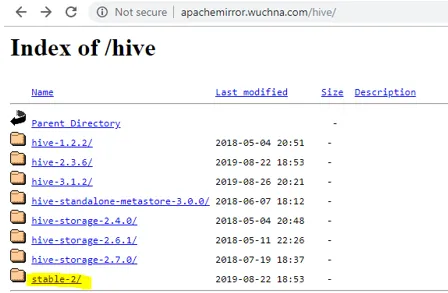
- La première chose que nous devons faire est de télécharger la version de la ruche qui peut être effectuée en cliquant sur le lien ci-dessous: http://apachemirror.wuchna.com/hive/
- Le lien ci-dessus donnera le lien à partir duquel vous devez choisir stable-2 surligné ci-dessous en jaune:
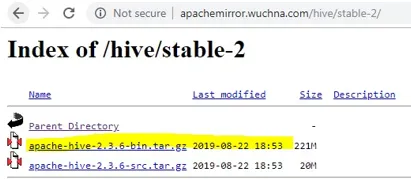
- Après avoir ouvert stable-2, choisissez le fichier bin (surligné en jaune dans la capture d'écran) et faites un clic droit et "copier l'adresse du lien".
Étapes pour installer Hive
Voici les étapes pour installer la ruche:
Étape 1: téléchargez le fichier tar.
http://apachemirror.wuchna.com/hive/stable-2/apache-hive-2.3.6-bin.tar.gz0
Étape 2: extraire le fichier.
sudo tar zxvf /Downloads/apache-hive-* -C /usr/local
Étape 3: déplacez les fichiers apache vers le répertoire / usr / local / hive.
sudo mv /usr/local/apache-hive-* /usr/local/hive
Étape 4: configurer l'environnement Hive en ajoutant les lignes suivantes au fichier ~ / .bashrc
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:.
export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.
Étape 5: exécutez le fichier bashrc.
$ source ~/.bashrc
Étape 6: Configuration de la ruche - Modifiez le fichier hive-env.sh pour l'ajouter:
export HADOOP_HOME=/usr/local/Hadoop
Étape 7: Modifier en utilisant les commandes ci-dessous:
$ cd $HIVE_HOME/conf
$ cp hive-env.sh.template hive-env.sh
- Maintenant, pour vérifier que la ruche est installée ou non, utilisez la commande hive-version.
- Ici, la version ruche entre dans la coquille de la ruche, ce qui signifie que la ruche est installée. Cependant, dans mon cas, c'est l'ancienne version qui donne l'avertissement.

Conclusion - Installation de la ruche
Hive ouvre le Big Data à beaucoup de gens en raison de sa facilité et de sa nature similaire à SQL comme le langage de requête et les interfaces. Hive est construit sur le noyau Hadoop car il utilise Mapreduce pour l'exécution. Il est très facile de récupérer les données et d'effectuer le traitement des Big Data.
Articles recommandés
Ceci est un guide d'installation de Hive. Ici, nous discutons de certaines conditions préalables pour installer la ruche sur n'importe quelle machine et comment installer la ruche par étapes pour une meilleure compréhension. Vous pouvez également consulter nos autres articles connexes pour en savoir plus-
- Qu'est-ce qu'une ruche?
- Commandes Hive
- Comment installer Hive
- Qu'est-ce que Pig?