

Différences entre Sqoop et Flume
Sqoop est un produit du logiciel Apache. Sqoop extrait des informations utiles de Hadoop, puis les transmet aux magasins de données externes. Avec l'aide de Sqoop, nous pouvons importer des données à partir d'un SGBDR ou d'un ordinateur central dans HDFS. Flume provient également du logiciel Apache. Il collecte et déplace les données récursives générées. L'Apache Flume n'est pas seulement limité à l'agrégation des données du journal, mais les sources de données sont personnalisables et donc Flume peut être utilisé pour transporter des quantités massives de données. La meilleure façon de collecter, d'agréger et de déplacer de grandes quantités de données entre le système de fichiers distribués Hadoop et le SGBDR consiste à utiliser des outils tels que Sqoop ou Flume.
Discutons de ces deux outils couramment utilisés dans le but susmentionné.
Qu'est-ce que Sqoop
Pour utiliser Sqoop, un utilisateur doit spécifier l'outil que l'utilisateur souhaite utiliser et les arguments qui contrôlent l'outil particulier. Vous pouvez également exporter à nouveau les données dans un SGBDR à l'aide de Sqoop. La fonctionnalité d'exportation de Sqoop est utilisée pour extraire des informations utiles de Hadoop et les exporter vers les magasins de données structurées externes. Il fonctionne avec différentes bases de données comme Teradata, MySQL, Oracle, HSQLDB.
- Architecture Sqoop: -
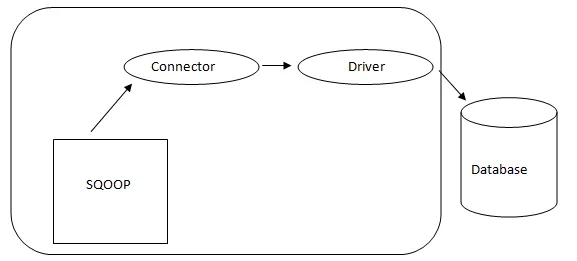
Architecture de Sqoop
Le connecteur dans un Sqoop est un plugin pour une source de base de données particulière, il est donc fondamental qu'il soit un élément de l'établissement de Sqoop. Malgré le fait que les pilotes sont des éléments spécifiques à la base de données et distribués par divers fournisseurs de bases de données, Sqoop lui-même est livré avec différents types de connecteurs utilisés pour la base de données courante et le système d'entreposage d'informations. Ainsi, Sqoop est également livré avec une variété de connecteurs mixtes. Sqoop offre un composant enfichable pour un réseau et un système externe idéaux. L'API Sqoop fournit une structure utile pour assembler de nouveaux connecteurs et par conséquent, tous les connecteurs de base de données peuvent être déposés dans l'installation Sqoop pour assurer la connectivité à différents systèmes de données.
Qu'est-ce que Flume
L'Apache Flume n'est pas seulement limité à l'agrégation des données du journal, mais les sources de données sont personnalisables et donc Flume peut être utilisé pour transporter d'énormes quantités de données, y compris, mais sans s'y limiter, les messages électroniques, les données générées par les médias sociaux, les données de trafic réseau et à peu près tout source de données possible.
Architecture Flume: - L' architecture Flume est basée sur des concepts à plusieurs cœurs:
- Événement Flume - il est représenté comme l'unité de flux de données, qui a une charge utile d'octets et un ensemble de chaînes avec des en-têtes de chaîne facultatifs. Flume considère un événement juste comme un blob générique d'octets.
- Agent Flume - Il s'agit d'un processus JVM qui héberge les composants tels que les canaux, le récepteur et les sources. Il a le potentiel de recevoir, de stocker et de transmettre les événements d'une source externe au niveau suivant.
- Flume Flow - c'est le moment où l'événement est généré.
- Client Flume - il se réfère à l'interface où le client opère au point d'origine de l'événement et le livre à l'agent Flume.
- Source - Une source est une source qui consomme des événements ayant un format spécifique et les délivre via un mécanisme spécifique.
- Channel - C'est un magasin passif où les événements sont tenus jusqu'à ce que l'évier le retire pour un transport ultérieur.
- Sink - Il supprime l'événement d'un canal et le place sur un référentiel externe comme HDFS. Il prend actuellement en charge la création de fichiers texte et de séquence et prend en charge la compression dans les deux types de fichiers.
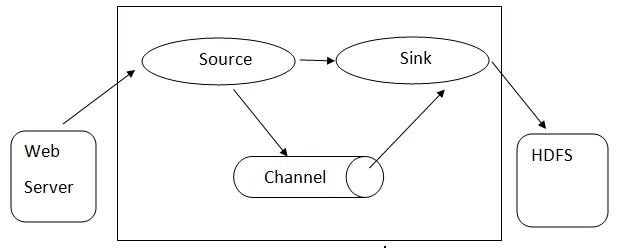
Architecture de Flume
Comparaison directe entre Sqoop et Flume (Infographie)
Voici la comparaison des 7 meilleurs entre Sqoop et Flume

Différences clés entre Sqoop et Flume
Nous savons maintenant qu'il existe de nombreuses différences entre Sqoop vs Flume, voici les différences les plus importantes entre elles données ci-dessous -
1. Sqoop est conçu pour échanger des informations de masse entre Hadoop et la base de données relationnelle.
Considérant que, Flume est utilisé pour collecter des données à partir de différentes sources qui génèrent des données concernant un cas d'utilisation particulier, puis transfèrent cette grande quantité de données à partir de ressources distribuées vers un référentiel centralisé unique.
2. Sqoop comprend également un ensemble de commandes qui vous permet d'inspecter la base de données avec laquelle vous travaillez. Ainsi, nous pouvons considérer Sqoop comme une collection d'outils connexes.
Lors de la collecte de la date, Flume met à l'échelle les données horizontalement et plusieurs agents Flume peuvent être mis en action pour collecter la date et les agréger. Par la suite, les journaux de données sont déplacés vers un magasin de données centralisé, à savoir le système de fichiers distribués Hadoop (HDFS).
3. Le facteur clé pour l'utilisation de Flume est que les données doivent être générées de manière continue et en continu. De même, Sqoop est le mieux adapté dans les situations où vos données vivent dans des systèmes de base de données tels que MySQL, Oracle, Teradata, PostgreSQL
Sqoop vs Flume (Tableau de comparaison)
| Base de comparaison | SQOOP | BUSE |
|
Nature de base | Sqoop fonctionne bien avec n'importe quel SGBDR doté de JDBC (Java Database Connectivity) comme Oracle, MySQL, Teradata, etc. | Flume fonctionne bien pour la source de données en streaming qui génère en continu, comme les journaux, JMS, l'annuaire, les rapports d'erreur, etc. |
| Flux de données | Sqoop spécifiquement utilisé pour le transfert de données parallèle. Pour cette raison, la sortie pourrait être dans plusieurs fichiers | Flume est utilisé pour collecter et agréger des données en raison de sa nature distribuée. |
| Événements pilotés | Sqoop n'est pas déterminé par les événements. | Flume est entièrement piloté par les événements. |
| Architecture | Sqoop suit une architecture basée sur les connecteurs, ce qui signifie que les connecteurs savent comment se connecter à une autre source de données. | Flume suit une architecture basée sur un agent, où le code qui y est écrit est connu comme un agent chargé de récupérer les données. |
| Où utiliser | Principalement utilisé pour copier des données plus rapidement, puis les utiliser pour générer des résultats analytiques. | Généralement utilisé pour extraire des données lorsque les entreprises souhaitent analyser les modèles, les causes profondes ou l'analyse des sentiments à l'aide de journaux et des médias sociaux. |
| Performance | Il réduit les charges de stockage et de traitement excessives en les transférant vers d'autres systèmes et offre des performances rapides. | Flume est tolérant aux pannes, robuste et dispose d'un mécanisme de fiabilité tenable pour le basculement et la récupération. |
| Historique des versions | La première version d'Apache Sqoop a été lancée en mars 2012. La version stable actuelle est la 1.4.7 | La première version stable 1.2.0 d'Apache Flume a été lancée en juin 2012. La version stable actuelle est Apache Flume Version 1.8.0. |
Conclusion - Sqoop vs Flume
Comme vous l'avez appris ci-dessus, Sqoop et Flume sont principalement deux outils d'ingestion de données utilisés dans le monde du Big Data. Si vous devez ingérer des données de journal textuelles dans Hadoop / HDFS, Flume est le bon choix pour ce faire. Si vos données ne sont pas générées régulièrement, Flume fonctionnera toujours, mais ce sera une surpuissance pour cette situation. De même, Sqoop n'est pas le meilleur choix pour la gestion des données événementielles.
Articles recommandés
Cela a été un guide pour les différences entre Sqoop vs Flume, leur signification, la comparaison tête à tête, les différences clés, le tableau de comparaison et la conclusion. cet article contient toutes les différences utiles entre Sqoop et Flume. Vous pouvez également consulter les articles suivants pour en savoir plus
- Hadoop vs Teradata - Différences utiles à apprendre
- 5 différence la plus importante entre Apache Kafka et Flume
- Big Data vs Apache Hadoop - Comparaison des 4 meilleurs que vous devez apprendre
- 5 différence la plus importante entre Apache Kafka et Flume
- Exploration de texte importante vs traitement du langage naturel - Les 5 meilleures comparaisons