

Questions et réponses d'entrevue Splunk - Introduction
Vous avez donc finalement trouvé votre emploi de rêve dans Splunk, mais vous vous demandez comment résoudre l'interview Splunk et quelles pourraient être les probables questions d'entrevue Splunk pour 2018. Chaque entretien est différent et la portée d'un travail est également différente. Gardant cela à l'esprit, nous avons conçu les questions et réponses d'entrevue Splunk les plus courantes pour 2018 pour vous aider à réussir votre entrevue.Vous trouverez ci-dessous les principales questions et réponses d'entrevue Splunk les plus utiles. Ces questions principales sont divisées en deux parties:
Partie 1 - Questions d'entrevue Splunk (de base)
Cette première partie couvre les questions et réponses d'entrevue Splunk de base.
1. Qu'est-ce que Splunk? Pourquoi Splunk est-il utilisé pour analyser les données machine?
Répondre:
Microsoft Excel est l'un des outils d'analyse les plus utilisés et l'inconvénient est qu'Excel ne peut charger que jusqu'à 1048576 lignes et que les données de la machine sont généralement énormes. Splunk est pratique pour traiter les données générées par la machine (big data), les données des serveurs, des appareils ou des réseaux peuvent être facilement chargées dans Splunk et peuvent être analysées pour vérifier la visibilité des menaces, la conformité, la sécurité, etc., elles peuvent également être utilisées pour la surveillance des applications.
2.Expliquez comment fonctionne Splunk
Répondre:
Ce sont les questions d'entrevue Splunk courantes posées dans une interview. Les données sont chargées dans Splunk à l'aide du redirecteur qui agit comme une interface entre l'environnement Splunk et le monde extérieur, puis ces données sont transmises à un indexeur où les données sont stockées localement ou sur un cloud. L'indexeur indexe les données machine et les stocke sur le serveur. Search Head est l'interface graphique qui est fournie par Splunk pour rechercher et analyser (recherche, visualise, analyse et exécute diverses autres fonctions) les données.
Le serveur de déploiement gère tous les composants de Splunk comme l'indexeur, le redirecteur et la tête de recherche dans l'environnement Splunk. 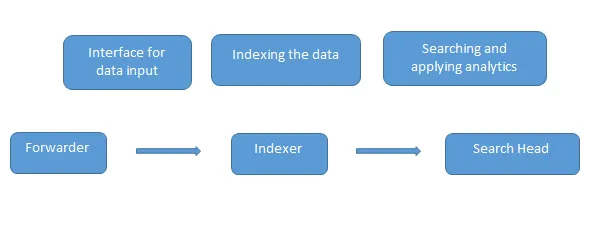
3. Quels sont les numéros de port courants utilisés par Splunk?
Réponse :
Les numéros de ports courants sur lesquels les services sont exécutés (par défaut) sont:
| Un service | Numéro de port |
| API de gestion / REST | 8089 |
| Tête de recherche / Indexeur | 8000 |
| Tête de recherche | 8065, 8191 |
| Noeud homologue de cluster d'indexeur / membre de cluster de tête de recherche | 9887 |
| Indexeur | 9997 |
| Indexeur / Transitaire | 514 |
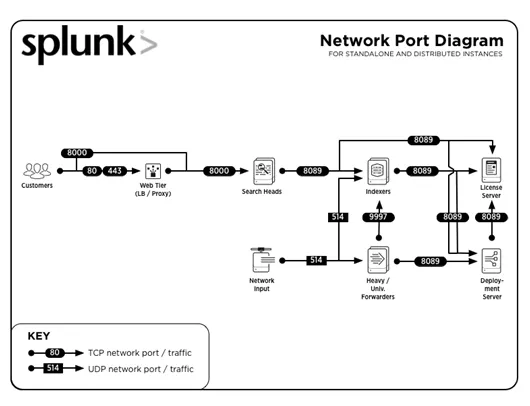
Passons aux prochaines questions d'entrevue Splunk.
4. Pourquoi utiliser uniquement Splunk?
Répondre:
Il existe de nombreuses alternatives pour Splunk qui lui donnent beaucoup de concurrence, certaines d'entre elles sont les suivantes:
• ELK / Logstash (open source)
Elasticsearch est utilisé pour la recherche, c'est comme la tête de recherche dans Splunk, le journal de stockage est pour la collecte de données qui est similaire au transitaire utilisé dans Splunk, et Kibana est utilisé pour la visualisation des données (la tête de recherche fait de même dans Splunk)
• Graylog (open source avec version commerciale)
Graylog est encore un autre outil qui a été nommé l'année dernière avec sa version 1.0. Semblable à la pile ELK, Graylog a également différents composants, il utilise Elasticsearch comme composant principal, mais les données sont stockées dans Mongo DB et utilisent Apache Kafka. Il a deux versions, une version de base qui est disponible gratuitement et la version d'entreprise qui comprend des fonctions telles que l'archivage.
• Sumo Logic (service cloud)
Donc, ce qui fait de Splunk le meilleur de tous, c'est que Splunk est un package unique du collecteur de données, du stockage et de l'outil d'analyse intégré. Splunk est également évolutif et fournit un support / aide professionnelle pour son édition entreprise.
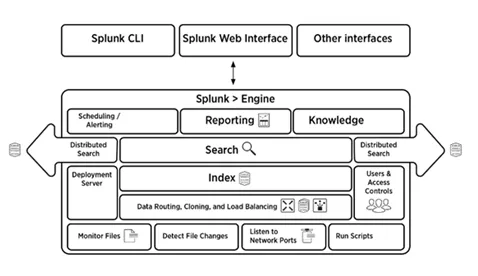
5. Expliquez brièvement l'architecture Splunk
Répondre:
L'image ci-dessous donne un bref aperçu de l'architecture Splunk et de ses composants.
Partie 2 - Questions d'entrevue Splunk (Avancé)
Voyons maintenant les questions avancées de l'entretien Splunk.
6. Quels sont les composants de l'architecture Splunk?
Répondre:
L'architecture Splunk comprend quatre composants. Elles sont:
- Indexeur: indexe les données machine
- Transitaire: transfère les journaux à indexer
- Tête de recherche: fournit une interface graphique pour la recherche
- Serveur de déploiement: gère les composants Splunk (indexeur, redirecteur et tête de recherche) dans un environnement distribué
7. Donnez quelques cas d'utilisation d'objets de connaissance.
Réponse :
Telles sont les questions fréquemment posées lors d'un entretien avec Splunk. Les objets de connaissances peuvent être utilisés dans de nombreux domaines. Quelques exemples sont:
Surveillance des applications: cela peut être utilisé pour surveiller les applications en temps réel avec des alertes configurées qui avertiront les administrateurs / utilisateurs lorsqu'une application se bloque.
Sécurité physique: en cas d'inondation / volcanique, etc., les données peuvent être utilisées pour tirer des informations si votre organisation traite ces données.
Sécurité du réseau: vous pouvez créer un environnement sécurisé en mettant sur liste noire l'IP des appareils inconnus, réduisant ainsi les fuites de données dans n'importe quelle organisation.
Gestion des employés: l' attrition des employés est l'un des défis auxquels est confrontée toute organisation et pendant la période de préavis, l'activité de l'employé peut être suivie afin de protéger les données de l'organisation, surveillant ainsi son activité et limitant tout autre employé en période de préavis à ne pas faire de même. .
8. expliquer le facteur de recherche (SF) et le facteur de réplication (RF)
Répondre:
Ce sont les terminologies utilisées dans les techniques de clustering Splunk. Le cluster d'indexeur est un groupe spécialement configuré d'indexeurs Splunk Enterprise qui réplique les données externes et est utilisé pour la reprise après sinistre.
En termes de recherche de documentation Splunk, le facteur peut être décrit comme «Le nombre de copies consultables des données qu'un cluster d'indexeur conserve. La valeur par défaut du facteur de recherche est de 2 pouces tandis que le facteur de réplication est défini comme le nombre de copies de données que le cluster conserve.
Le cluster d'indexeur a à la fois un facteur de recherche et un facteur de réplication tandis que le cluster principal de recherche n'a qu'un facteur de recherche
Passons aux prochaines questions d'entrevue Splunk.
9. Que sont les godets Splunk? Expliquez le cycle de vie du compartiment.
Répondre:
Les répertoires dans lesquels les données indexées sont stockées sont connus sous le nom de compartiments Splunk et ceux-ci ont des événements d'une certaine période. Le cycle de vie du godet Splunk comprend quatre étapes: chaud, chaud, froid, congelé et décongelé.
- Hot - Ce compartiment contient les données récemment indexées et est ouvert pour l'écriture.
- Chaud - Une fois les données tombées dans le hot bucket en fonction de vos politiques de données, elles sont déplacées vers des buckets chauds
- Froid - L'étape suivante après chaud est l'étape froide où les données ne peuvent pas être modifiées.
- Gelé - Par défaut, l'indexeur supprime les données des compartiments gelés, mais celles-ci peuvent également être archivées.
- Décongelé - La récupération d'informations à partir de fichiers archivés (seau gelé) est appelée décongélation.
10. Pourquoi devrions-nous utiliser Splunk Alert? Quelles sont les différentes options lors de la configuration des alertes?
Répondre:
L'état d'être attentif à toute erreur possible est connu sous le nom d'alerte et dans Splunk, des alertes d'environnement peuvent survenir en raison d'échecs de connexion ou de violations de sécurité ou d'une violation des règles créées par l'utilisateur.
Par exemple, envoyer des notifications ou un rapport des utilisateurs qui n'ont pas réussi à se connecter après avoir utilisé leurs trois tentatives dans un portail à l'administrateur de l'application.
Les différentes options disponibles lors de la configuration des alertes sont les suivantes:
- Un webhook peut être créé pour écrire les alertes sur hipchat ou GitHub.
- Ajoutez des résultats, .csv ou pdf ou en ligne avec le corps du message afin que la cause première de l'alerte puisse être identifiée.
- Les tickets peuvent être créés et les alertes peuvent être limitées depuis une machine ou une IP.
Article recommandé
Ceci a été un guide pour la liste des questions et réponses d'entrevue Splunk afin que le candidat puisse réprimer facilement ces questions et réponses d'entrevue Splunk. Vous pouvez également consulter les articles suivants pour en savoir plus -
- Questions d'entretiens chez SAS System - Top 10 des questions utiles
- 10 excellentes questions d'entrevue Tableau que vous devez savoir
- 15 questions et réponses d'entrevue Oracle les plus réussies
- Questions d'entrevue sur la sécurité du réseau - Top et les plus posées
- Splunk vs Nagios