

Présentation de l'architecture d'exploration de données
L'exploration de données est le moyen de trouver et d'explorer les modèles de base ou de niveau avancé dans un ensemble compliqué de grands ensembles de données qui implique les méthodes placées à l'intersection des statistiques, de l'apprentissage automatique et également des systèmes de bases de données. On peut dire qu'il s'agit d'un domaine interdisciplinaire de la statistique et de l'informatique où le but est d'extraire les informations à l'aide de méthodes et de techniques intelligentes d'un ensemble particulier de données au moyen de l'extraction et ainsi de transformer les données. Les activités de gestion des données et de prétraitement des données ainsi que les considérations d'inférence sont également prises en considération. Dans cet article, nous allons approfondir l'architecture de l'exploration de données.
Architecture d'exploration de données
L'exploration de données est la technique d'extraction de connaissances intéressantes d'un ensemble d'énormes quantités de données qui sont ensuite stockées dans de nombreuses sources de données telles que les systèmes de fichiers, les entrepôts de données, les bases de données. Les principaux composants de l'architecture d'exploration de données impliquent -
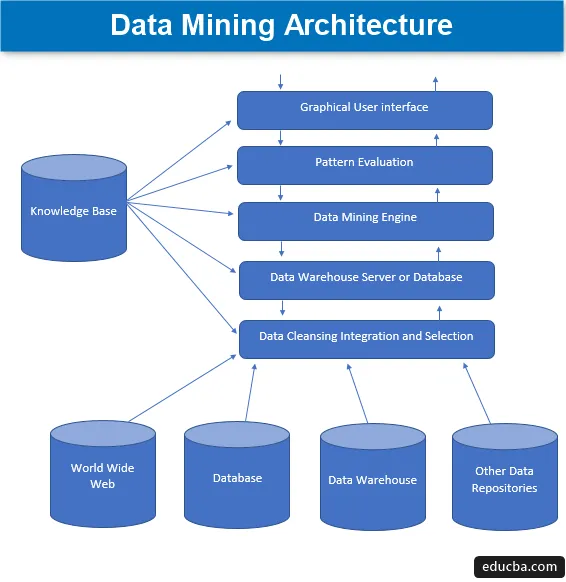
1. Sources de données
Une grande variété de documents actuels tels que l'entrepôt de données, la base de données, www ou populairement appelé un World Wide Web qui devient les sources de données réelles. La plupart du temps, il peut également arriver que les données ne soient présentes dans aucune de ces sources d'or, mais uniquement sous la forme de fichiers texte, de fichiers simples ou de fichiers de séquence ou de feuilles de calcul, puis les données doivent être traitées de manière très de la même manière que le traitement se ferait sur les données reçues de sources d'or. La majeure partie de la majeure partie des données d'aujourd'hui est reçue d'Internet ou du World Wide Web, car tout ce qui est présent sur Internet aujourd'hui est des données sous une forme ou une autre qui forment une certaine forme d'unités de stockage d'informations.
Avant que les données ne soient traitées à l'avance, les différents processus par lesquels elles passent impliquent un nettoyage, une intégration et une sélection des données avant que les données ne soient finalement transmises à la base de données ou à l'un des serveurs EDW (Enterprise Data Warehouse). Le défi majeur qui se pose parfois avec cet ensemble de données est différents niveaux de sources et un large éventail de formats de données qui forment les composants de données. Par conséquent, les données ne peuvent pas être directement utilisées pour le traitement dans leur état naïf mais traitées, transformées et conçues de manière beaucoup plus utilisable. De cette façon, la fiabilité et l'exhaustivité des données sont également assurées. Ainsi, la première étape implique la collecte, le nettoyage et l'intégration des données, et le post que seules les données pertinentes sont transmises. Toute cette activité fait partie d'un ensemble distinct d'outils et de techniques.
2. Serveur ou base de données Data Warehouse
Le serveur de base de données est l'espace réel où les données sont contenues une fois qu'elles sont reçues des différents nombres de sources de données. Le serveur contient l'ensemble réel de données qui devient prêt à être traité et, par conséquent, le serveur gère la récupération des données. Toute cette activité est basée sur la demande de data mining de la personne.
3. Moteur d'exploration de données
Dans le cas de l'exploration de données, le moteur constitue le composant central et est la partie la plus vitale, ou pour dire la force motrice qui gère toutes les demandes et les gère et est utilisée pour contenir un certain nombre de modules. Le nombre de modules présents comprend des tâches d'exploration telles que la technique de classification, la technique d'association, la technique de régression, la caractérisation, la prédiction et le clustering, l'analyse de séries chronologiques, les Bayes naïfs, les machines à vecteurs de support, les méthodes d'ensemble, les techniques de boosting et d'ensachage, les forêts aléatoires, les arbres de décision, etc.
4. Modules d'évaluation des modèles
Cette technique d'évaluation des modules est principalement chargée de mesurer l'intérêt de tous les modèles qui sont utilisés pour calculer le niveau de base de la valeur de seuil et est également utilisée pour interagir avec le moteur d'exploration de données afin de se coordonner dans l'évaluation des autres modules. Dans l'ensemble, l'objectif principal de cette composante est de rechercher et de rechercher tous les modèles intéressants et utilisables qui pourraient rendre les données de meilleure qualité.
5. Interface utilisateur graphique
Lorsque les données sont communiquées avec les moteurs et entre divers modèles d'évaluation des modules, il devient nécessaire d'interagir avec les différents composants présents et de les rendre plus conviviaux afin que l'utilisation efficace et effective de tous les composants actuels puisse être faite et donc pose le besoin d'une interface utilisateur graphique communément appelée GUI.
Ceci est utilisé pour établir un sentiment de contact entre l'utilisateur et le système d'exploration de données, aidant ainsi les utilisateurs à accéder et à utiliser le système de manière efficace et facile pour les garder dépourvus de toute complexité apparue au cours du processus. Il s'agit d'une forme d'abstraction où seuls les composants pertinents sont affichés pour les utilisateurs et toutes les complexités et fonctionnalités responsables de la construction du système sont cachées par souci de simplicité. Chaque fois que l'utilisateur soumet une requête, le module interagit ensuite avec l'ensemble global d'un système d'exploration de données pour produire une sortie pertinente qui pourrait être facilement montrée à l'utilisateur d'une manière beaucoup plus compréhensible.
6. Base de connaissances
C'est le composant qui constitue la base du processus global d'exploration de données car il aide à guider la recherche ou à évaluer l'intérêt des modèles formés. Cette base de connaissances comprend les croyances des utilisateurs ainsi que les données obtenues à partir des expériences des utilisateurs qui sont à leur tour utiles dans le processus d'exploration de données. Le moteur peut obtenir son ensemble d'entrées à partir de la base de connaissances créée et ainsi fournir des résultats plus efficaces, précis et fiables.
L'exploration de données est l'une des techniques les plus importantes aujourd'hui qui traite de la gestion des données et du traitement des données qui constitue l'épine dorsale de toute organisation. L'analyse des données dans n'importe quelle organisation apportera des résultats fructueux. Chaque composant de l'architecture et de la technique d'exploration de données a sa propre façon de s'acquitter de ses responsabilités et de terminer efficacement l'exploration de données. Les différents modules sont nécessaires pour interagir correctement afin de produire un résultat précieux et de mener à bien la procédure complexe d'exploration de données en fournissant le bon ensemble d'informations à l'entreprise.
Articles recommandés
Il s'agit d'un guide de l'architecture d'exploration de données. Nous discutons ici des principaux composants de l'architecture d'exploration de données. Vous pouvez également consulter nos autres articles suggérés pour en savoir plus -
- Outil d'exploration de données
- Avantages de l'exploration de données
- Qu'est-ce que le clustering dans l'exploration de données?
- Questions et réponses d'entrevue HTML5
- Techniques d'apprentissage en ensemble les plus utilisées
- Algorithmes de modèles dans l'exploration de données