
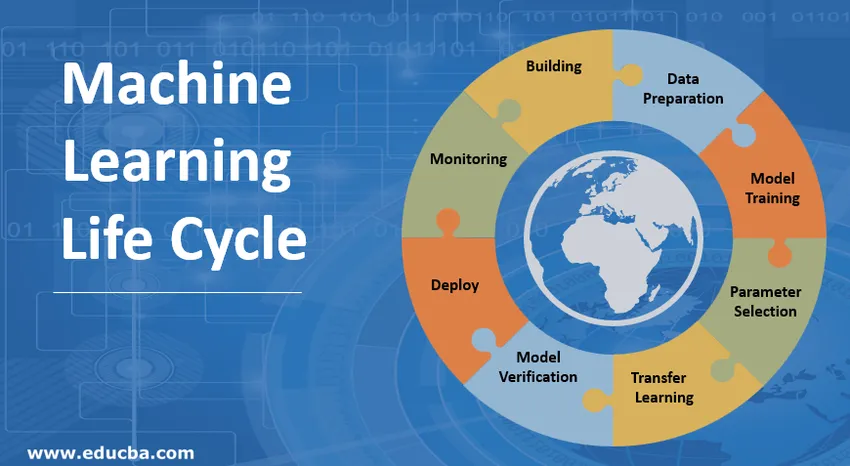
Introduction au cycle de vie du Machine Learning (ML)
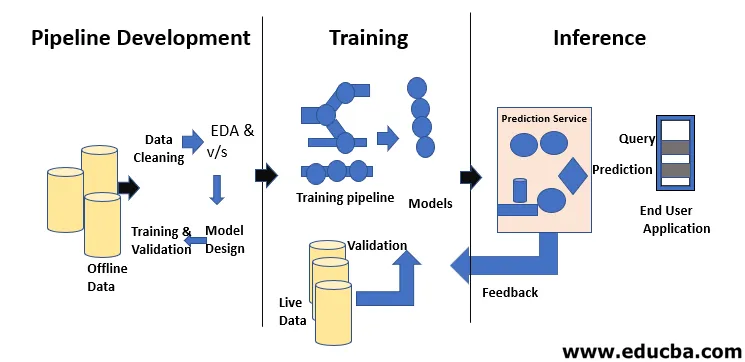
Le cycle de vie du Machine Learning consiste à acquérir des connaissances grâce aux données. Le cycle de vie de l'apprentissage automatique décrit un processus en trois phases utilisé par les scientifiques et ingénieurs de données pour développer, former et servir des modèles. Le développement, la formation et le service de modèles d'apprentissage automatique sont le résultat d'un processus appelé cycle de vie d'apprentissage automatique. Il s'agit d'un système qui utilise des données comme entrée, ayant la capacité d'apprendre et d'améliorer l'utilisation d'algorithmes sans être programmé pour le faire. Le cycle de vie de l'apprentissage automatique comporte trois phases, comme illustré dans la figure ci-dessous: développement de pipeline, formation et inférence.
La première étape du cycle de vie de l'apprentissage automatique consiste à transformer des données brutes en un ensemble de données nettoyé, cet ensemble de données étant souvent partagé et réutilisé. Si un analyste ou un data scientist qui rencontre des problèmes dans les données reçues, il doit accéder aux données d'origine et aux scripts de transformation. Il existe diverses raisons pour lesquelles nous souhaitons revenir aux versions antérieures de nos modèles et données. Par exemple, la recherche de la meilleure version antérieure peut nécessiter une recherche dans de nombreuses versions alternatives car les modèles dégradent inévitablement leur pouvoir prédictif. Il existe de nombreuses raisons à cette dégradation, comme un changement dans la distribution des données qui peut entraîner une baisse rapide du pouvoir prédictif en compensation des erreurs. Pour diagnostiquer cette baisse, il peut être nécessaire de comparer les données de formation avec des données en direct, de recycler le modèle, de revoir les décisions de conception antérieures ou même de repenser le modèle.
Apprendre des erreurs
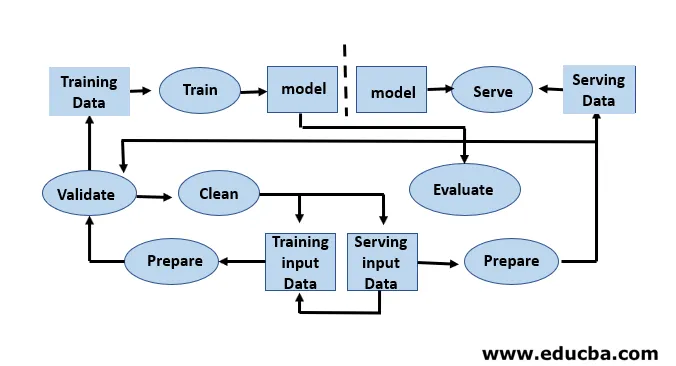
Le développement de modèles nécessite une formation et des jeux de données séparés. Une utilisation excessive des données de test pendant la formation peut entraîner une généralisation et des performances médiocres, car elles peuvent entraîner un sur-ajustement. Le contexte joue ici un rôle vital, il est donc nécessaire de comprendre quelles données ont été utilisées pour former les modèles prévus et avec quelles configurations. Le cycle de vie du machine learning est piloté par les données car le modèle et le résultat de la formation sont liés aux données sur lesquelles il a été formé. Un aperçu d'un pipeline de machine learning de bout en bout avec un point de vue de données est illustré dans la figure ci-dessous:
Étapes impliquées dans le cycle de vie du Machine Learning
Le développeur de Machine Learning effectue constamment des expériences avec de nouveaux ensembles de données, modèles, bibliothèques de logiciels et paramètres de réglage afin d'optimiser et d'améliorer la précision du modèle. Étant donné que les performances du modèle dépendent entièrement des données d'entrée et du processus de formation.
1. Construire le modèle d'apprentissage automatique
Cette étape décide du type du modèle en fonction de l'application. Il constate également que l'application du modèle dans la phase d'apprentissage du modèle afin qu'ils puissent être conçus correctement en fonction du besoin d'une application envisagée. Divers modèles d'apprentissage automatique sont disponibles, tels que le modèle supervisé, le modèle non supervisé, les modèles de classification, les modèles de régression, les modèles de regroupement et les modèles d'apprentissage par renforcement. Un aperçu détaillé est illustré dans la figure ci-dessous:
2. Préparation des données
Une variété de données peut être utilisée comme entrée à des fins d'apprentissage automatique. Ces données peuvent provenir d'un certain nombre de sources, telles qu'une entreprise, des sociétés pharmaceutiques, des appareils IoT, des entreprises, des banques, des hôpitaux, etc. De grands volumes de données sont fournis au stade de l'apprentissage de la machine, car à mesure que le nombre de données augmente, il s'aligne vers donnant les résultats souhaités. Ces données de sortie peuvent être utilisées pour l'analyse ou alimentées en entrée dans d'autres applications ou systèmes d'apprentissage automatique pour lesquels elles agiront comme une graine.
3. Formation modèle
Cette étape concerne la création d'un modèle à partir des données qui lui sont données. À ce stade, une partie des données d'apprentissage est utilisée pour trouver des paramètres de modèle tels que les coefficients d'un polynôme ou les poids de l'apprentissage automatique, ce qui aide à minimiser l'erreur pour l'ensemble de données donné. Les données restantes sont ensuite utilisées pour tester le modèle. Ces deux étapes sont généralement répétées plusieurs fois afin d'améliorer les performances du modèle.
4. Sélection des paramètres
Elle implique la sélection des paramètres associés à la formation qui sont également appelés hyperparamètres. Ces paramètres contrôlent l'efficacité du processus de formation et, par conséquent, en fin de compte, les performances du modèle en dépendent. Ils sont très cruciaux pour la production réussie du modèle d'apprentissage automatique.
5. Transfert d'apprentissage
Puisqu'il y a beaucoup d'avantages à réutiliser des modèles d'apprentissage automatique dans divers domaines. Ainsi, malgré le fait qu'un modèle ne peut pas être transféré directement entre différents domaines, il est donc utilisé pour fournir un matériel de départ pour commencer la formation d'un modèle de l'étape suivante. Ainsi, il réduit considérablement le temps de formation.
6. Vérification du modèle
L'entrée de cette étape est le modèle formé produit par l'étape d'apprentissage du modèle et la sortie est un modèle vérifié qui fournit des informations suffisantes pour permettre aux utilisateurs de déterminer si le modèle convient à l'application prévue. Ainsi, cette étape du cycle de vie de l'apprentissage automatique concerne le fait qu'un modèle fonctionne correctement lorsqu'il est traité avec des entrées invisibles.
7. Déployer le modèle d'apprentissage automatique
À cette étape du cycle de vie du Machine Learning, nous appliquons pour intégrer des modèles de Machine Learning dans les processus et les applications. Le but ultime de cette étape est la fonctionnalité appropriée du modèle après le déploiement. Les modèles doivent être déployés de manière à pouvoir être utilisés pour l'inférence et mis à jour régulièrement.
8. Suivi
Elle implique l'inclusion de mesures de sécurité pour garantir le bon fonctionnement du modèle pendant sa durée de vie. Pour ce faire, une gestion et une mise à jour appropriées sont nécessaires.
Avantage du cycle de vie de l'apprentissage automatique
L'apprentissage automatique offre les avantages de la puissance, de la vitesse, de l'efficacité et de l'intelligence grâce à l'apprentissage sans les programmer explicitement dans une application. Il offre des opportunités d'amélioration des performances, de la productivité et de la robustesse.
Conclusion - Cycle de vie de l'apprentissage automatique
Les systèmes d'apprentissage automatique deviennent de plus en plus importants de jour en jour, car la quantité de données impliquées dans diverses applications augmente rapidement. La technologie d'apprentissage automatique est au cœur des appareils intelligents, des appareils électroménagers et des services en ligne. Le succès de l'apprentissage automatique peut être étendu aux systèmes critiques pour la sécurité, à la gestion des données et au calcul haute performance, qui recèlent un grand potentiel pour les domaines d'application.
Articles recommandés
Ceci est un guide du cycle de vie de l'apprentissage automatique. Nous discutons ici de l'introduction, Apprendre des erreurs, étapes impliquées dans le cycle de vie du Machine Learning et avantages. Vous pouvez également consulter nos autres articles suggérés pour en savoir plus–
- Entreprises d'intelligence artificielle
- Analyse d'ensemble QlikView
- Écosystème IoT
- Modélisation des données Cassandra