
Différence entre Hadoop et Redshift
Hadoop est un framework open source développé par Apache Software Foundation avec ses principaux avantages d'évolutivité, de fiabilité et d'informatique distribuée. Le traitement des données, le stockage, l'accès, la sécurité sont plusieurs types de fonctionnalités disponibles sur l'écosystème Hadoop. HDFS a un débit élevé, ce qui signifie qu'il est capable de gérer de grandes quantités de données avec une capacité de traitement parallèle. Redshift est un service Web d'hébergement cloud développé par l'unité Amazon Web Services au sein d'Amazon.com Inc., à partir des services existants fournis par Amazon. Il est utilisé pour concevoir un entrepôt de données à grande échelle dans le cloud. Redshift est un service d'entrepôt de données à l'échelle du pétaoctet qui est entièrement géré et rentable pour fonctionner sur de grands ensembles de données.
Étudions plus en détail Hadoop et Redshift en détail:
Hadoop HDFS a une capacité de tolérance aux pannes élevée et a été conçu pour fonctionner sur des systèmes matériels à faible coût. Hadoop peut gérer une taille de type minimale de TeraBytes à GigaBytes de fichiers dans son système. HDFS est une architecture maître-esclave composée de nœuds de nom et de nœuds de données où le nœud de nom contient des métadonnées et le nœud de données contient des données réelles à traiter ou à exploiter.
RedShift utilise différentes techniques de chargement de données telles que les rapports BI (Business Intelligence), les outils analytiques et l'exploration de données. Redshift fournit une console pour créer et gérer des clusters Amazon Redshift. Le composant principal de Redshift Data Warehouse est un cluster.
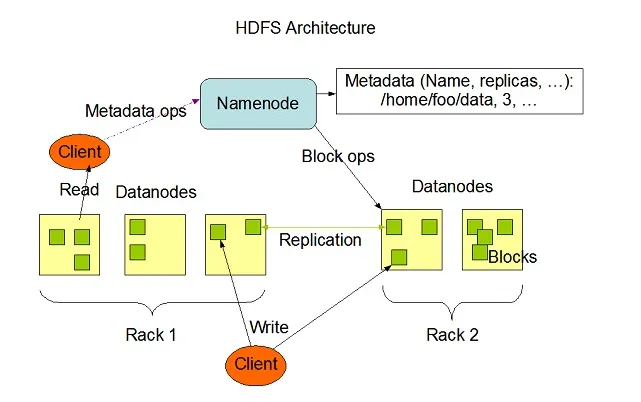
Source de l'image: Apache.org
Architecture RedShift:
 Source de l'image: Amazon.com
Source de l'image: Amazon.com
Comparaison directe entre Hadoop et Redshift (infographie):
Ci-dessous, le top 10 de la comparaison entre Hadoop et Redshift:

Différences clés entre Hadoop et Redshift:
Ci-dessous, les principales différences entre Hadoop et Redshift sont les suivantes
1.L'architecture Hadoop HDFS (Hadoop Distributed File System) a des nœuds de nom et des nœuds de données, tandis que Redshift a un nœud leader et des nœuds de calcul où les nœuds de calcul seront partitionnés en tranches.
2. Hadoop fournit une interface de ligne de commande pour interagir avec le système de fichiers tandis que RedShift possède une console de gestion pour interagir avec les services de stockage Amazon tels que S3, DynamoDB, etc.,
3.Les opérations de base de données doivent être configurées par les développeurs. Dans Redshift, automatise les opérations de la base de données en analysant les plans d'exécution.
4. Hadoop prend en charge plusieurs outils tiers pour être intégré facilement tandis que Redshift ne prend en charge que les produits développés par Amazon dans son cloud.
En termes de conception architecturale Hadoop, le réseau, le stockage, la sécurité et les performances ont été considérés comme des éléments principaux, tandis que dans Redshift, ces éléments peuvent être configurés facilement et de manière flexible à l'aide de la console de gestion du cloud Amazon.
6. Hadoop est une architecture de système de fichiers basée sur des interfaces de programmation d'applications Java (API) tandis que Redshift est basé sur un système de gestion de base de données de modèle relationnel (RDBMS).
7. Hadoop peut avoir des intégrations avec différents fournisseurs et Redshift n'a aucun support dans ce cas où Amazon est leur seul fournisseur. Et si un utilisateur n'est pas satisfait du service? Dans ce cas, Hadoop est un avantage.
8.La plupart des entreprises existantes utilisent encore Hadoop tandis que les nouveaux clients choisissent RedShift.
En termes de performances, Hadoop est toujours en retard et Redshift l'emporte toujours en cas d'exécution de requêtes sur de gros volumes de données.
10. Hadoop utilise le modèle de programmation Map Reduce pour exécuter des travaux. Amazon Redshift utilise Elastic Map Reduce d'Amazon.
11. Hadoop utilise le modèle de programmation Map Reduce pour exécuter des travaux. Amazon Redshift utilise Elastic Map Reduce d'Amazon.
12. Hadoop est préférable d'exécuter quotidiennement des travaux par lots qui deviennent moins chers tandis que Redshift sort moins cher en cas de technologie OLAP (Online Analytical Processing) qui existe derrière de nombreux outils de Business Intelligence.
13. Hadoop est 10 fois plus lent que Redshift dans l'exécution des requêtes de la même manière que Hadoop est 10 fois plus cher que Redshift, ce qui fait que Hadoop est le moins choisi avant Redshift.
14.En termes de chargement de données également, Hadoop a été à l'origine de Redshift en termes de temps mis par le système pour charger les données du stockage dans son système de traitement de fichiers.
15.Hadoop peut être utilisé pour les stockages à faible coût, l'archivage de données, les lacs de données, l'entreposage de données et l'analyse de données, tandis que Redshift relève des capacités d'entrepôt de données, ce qui limite l'utilisation polyvalente.
16.La plate-forme Hadoop fournit une assistance à divers fournisseurs externes et à ses propres projets Apache tels que Storm, Spark, Kafka, Solr etc., et d'autre part, Redshift a une prise en charge d'intégration limitée avec ses seuls produits Amazon.
Tableau de comparaison Hadoop vs Redshift
| BASE POUR
COMPARAISON | HADOOP | REDSHIFT |
| Disponibilité | Framework Open Source par Apache Projects | Services payants fournis par Amazon |
| la mise en oeuvre | Fourni par les fournisseurs Hortonworks et Cloudera, etc., | Développé et fourni par Amazon |
| Performance | Les travaux Hadoop MapReduce sont plus lents | Redshift est plus rapide que le cluster Hadoop |
| Évolutivité | Limitations d'évolutivité | Être facilement down / upsized selon l'exigence |
| Tarification | Coûts de 200 $ par mois pour exécuter des requêtes | Le prix dépend de la région du serveur et moins cher que Hadoop
Par exemple: 20 $ / mois |
| La vitesse | Plus rapide mais plus lent que Redshift | 10 fois plus rapide que Hadoop |
| Vitesse de requête | Prend 1491 secondes pour exécuter des données de 1, 2 To | 155 secondes pour exécuter des données de 1, 2 To |
| Intégration de données | Flexible avec le système de fichiers local et n'importe quelle base de données | Peut charger des données depuis Amazon S3 ou DynamoDB uniquement |
| Format des données | Tous les formats de données sont pris en charge | Strict dans les formats de données tels que les formats de fichiers CSV |
| Facilité d'utilisation | Complexe et plus délicat pour gérer les activités d'administration | Sauvegarde automatisée et administration de l'entrepôt de données |
Conclusion - Hadoop vs Redshift
La déclaration finale pour conclure le grand gagnant de cette comparaison est Redshift qui gagne en termes de facilité d'exploitation, de maintenance et de productivité, alors que Hadoop manque en termes d'évolutivité des performances et de coût des services avec le seul avantage d'une intégration facile avec des outils tiers. et produits. Redshift a récemment évolué avec une croissance et une acceptation considérables par de nombreux clients et clients en raison de sa haute disponibilité et de son coût d'exploitation inférieur à Hadoop, ce qui le rend de plus en plus populaire. Mais jusqu'à présent, la plupart des sociétés Fortune 1000 existantes utilisaient des plates-formes Hadoop dans leurs architectures pour gérer les données clients.
Dans la plupart des cas, RedShift a été le meilleur choix à considérer pour les besoins commerciaux par tout client ou client afin de gérer les données volumineuses et sensibles de toutes les institutions financières ou les informations publiques avec plus d'intégrité et de sécurité des données.
En dehors de cela, Hadoop a ses propres avantages en tant que projet open source et était disponible depuis de nombreuses années, ce qui entraîne également le remplacement des systèmes existants en tant que processus entraînant des coûts. Le produit doit être finalement choisi en fonction de l'exigence et de la flexibilité plutôt que du prix ou de la popularité en fonction des besoins commerciaux déterminés.
Article recommandé:
Cela a été un guide pour Hadoop vs Redshift, leur signification, leur comparaison directe, leurs principales différences, leur tableau de comparaison et leur conclusion. Vous pouvez également consulter les articles suivants pour en savoir plus -
- Hadoop vs Hive - Découvrez les meilleures différences
- HADOOP vs RDBMS | Connaître les 12 différences utiles
- Apache Hadoop vs Apache Spark | Top 10 des comparaisons que vous devez savoir!
- Big Data vs Data Science - En quoi sont-ils différents?
- Guide sur Hadoop vs Spark
- Top 4 des fournisseurs d'hébergement cloud avec des fonctionnalités