

Différence entre Hadoop et HBase
Hadoop est un framework Java open source, utilisé pour gérer et traiter une énorme quantité de données structurées et non structurées. Hadoop est massivement évolutif et est donc utilisé pour traiter les charges de travail Big Data. Les mégadonnées sont stockées, accessibles et traitées sur le cluster fiable et extensible. HBase (base de données Hadoop) est une base de données non relationnelle et non seulement SQL, c'est-à-dire NoSQL qui s'exécute au sommet de Hadoop en tant que magasin de données volumineuses distribué et évolutif. Il s'agit d'une base de données open source dans laquelle les données sont stockées sous forme de lignes et de colonnes, dans cette cellule est une intersection de colonnes et de lignes.
Voici les principaux composants de l'architecture Hadoop:
- Système de fichiers distribués Hadoop (HDFS): Hadoop comprend un système de stockage distribué, le système de fichiers distribués Hadoop (HDFS). HDFS est l'architecture maître-esclave qui stocke les données à travers le cluster. Données réparties sur plusieurs nœuds esclaves par le nœud maître dans le bloc de formulaire. Le nœud maître est appelé Namenode et les nœuds esclaves sont appelés Datanode. HDFS est facilement extensible et stocke une énorme quantité de données sur Datanodes. HDFS a un facteur de réplication configurable avec la valeur par défaut 3 qui peut être modifiable.
- MapReduce: MapReduce est un paradigme de programmation, processus en parallèle sur un grand nombre d'ensembles de données sur le réseau. MapReduce fait référence à deux tâches différentes: mapper les données d'entrée dans lesquelles les données divisées en un sous-ensemble de données appelées tuples et réduire la tâche prend ces tuples de la carte en entrée et les combine pour former la sortie de l'original.
- Yarn: YARN signifie encore un autre navigateur de ressources qui calcule des ressources telles que la gestion du processeur et de la mémoire, la planification des demandes de ressources.
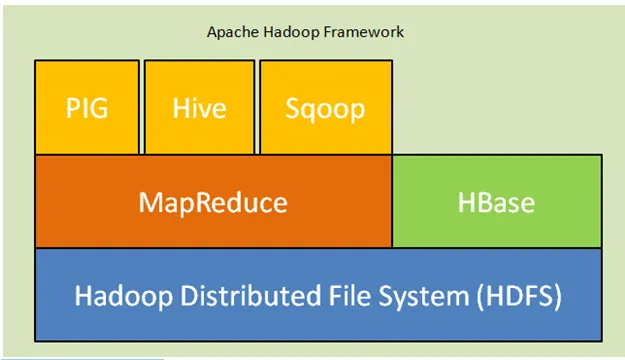
Fig. Apache Hadoop Framework
Le serveur de région sert des données pour les opérations de lecture / écriture. Toutes les données HBase sont stockées dans le fichier HDFS. Le HDFS Datanode stocke les données que le serveur de région gère. Le HDFS Namenode conserve les informations de métadonnées pour tous les blocs de données physiques qui composent les fichiers.
Le contrôle de version est utilisé pour suivre les modifications des cellules, ce qui permet de garder la trace de la version du contenu. De là, n'importe quelle version de contenu peut être récupérée. Chaque valeur de cellule inclut l'attribut «version» par rapport à l'horodatage pour récupérer la cellule. Chaque valeur de la carte est un tableau d'octets ininterrompu. La carte est indexée par une clé de ligne, une clé de colonne et un horodatage. L'architecture de HBase est des cartes hautement évolutives, clairsemées, distribuées, persistantes et triées en plusieurs dimensions.
Comparaison directe entre Hadoop et HBase (infographie)
Vous trouverez ci-dessous la principale différence entre Hadoop et HBase
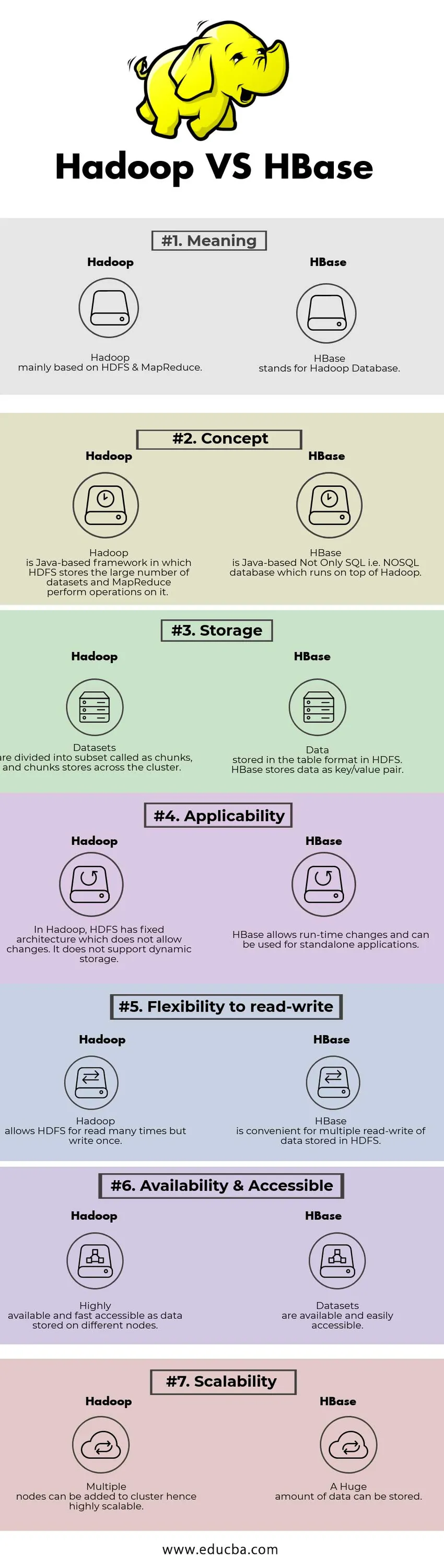
Différences clés entre Hadoop et HBase
La différence entre Hadoop et HBase est expliquée dans les points présentés ci-dessous:
- Hadoop n'est pas adapté au traitement analytique en ligne (OLAP) et HBase fait partie de l'écosystème Hadoop qui fournit un accès aléatoire en temps réel (lecture / écriture) aux données du système de fichiers Hadoop.
- La structure Hadoop est tolérante aux pannes par conception et prend en charge le transfert de données rapide entre les nœuds, même en cas de défaillance du système. HBase est une base de données non relationnelle et open source Not-Only-SQL qui s'exécute au-dessus de Hadoop. HBase appartient au type CP de théorème CAP (cohérence, disponibilité et tolérance de partition).
- Hadoop est le plus approprié pour effectuer des analyses par lots. Cependant, l'un de ses plus grands inconvénients est son incapacité à effectuer une analyse en temps réel, l'exigence de tendance de l'industrie informatique. HBase, d'autre part, peut gérer de grands ensembles de données et n'est pas approprié pour l'analyse par lots. Au lieu de cela, il est utilisé pour écrire / lire des données depuis Hadoop en temps réel.
- Hadoop et HBase sont capables de traiter des données structurées, semi-structurées et non structurées. Dans Hadoop, HDFS ne dispose pas d'un moteur de traitement en mémoire qui ralentit le processus d'analyse des données; car il utilise le vieux MapReduce pour le faire. HBase, au contraire, dispose d'un moteur de traitement en mémoire qui augmente considérablement la vitesse de lecture / écriture.
- Hadoop est très transparent dans son exécution de l'analyse des données. HBase, en revanche, étant une base de données NoSQL au format tabulaire, récupère les valeurs en les triant sous différentes valeurs de clé.
Tableau de comparaison Hadoop vs HBase
| BASE DE COMPARISION | Hadoop | HBase |
| Sens | Hadoop principalement basé sur HDFS et MapReduce. | HBase signifie Hadoop Database. |
| Concept | Hadoop est une infrastructure basée sur Java dans laquelle HDFS stocke le grand nombre d'ensembles de données et MapReduce effectue des opérations dessus. | HBase est une base de données non seulement SQL, c'est-à-dire NoSQL, qui s'exécute au-dessus de Hadoop. |
| Espace de rangement | Les ensembles de données sont divisés en sous-ensembles appelés en tant que blocs et en magasins de blocs à travers le cluster. | Données stockées au format tableau dans HDFS. HBase stocke les données sous forme de paire clé / valeur. |
| Applicabilité | Dans Hadoop, HDFS a une architecture fixe qui ne permet pas de modifications. Il ne prend pas en charge le stockage dynamique. | HBase permet des modifications au moment de l'exécution et peut être utilisé pour des applications autonomes. |
| Flexibilité en lecture-écriture | Hadoop permet à HDFS de lire plusieurs fois mais d'écrire une seule fois. | HBase est pratique pour la lecture-écriture multiple des données stockées dans HDFS |
| Disponibilité et accessible | Hautement disponible et accessible rapidement en tant que données stockées sur différents nœuds. | Les jeux de données sont disponibles et facilement accessibles |
| Évolutivité | Plusieurs nœuds peuvent être ajoutés au cluster, donc hautement évolutifs. | Une énorme quantité de données peut être stockée. |
Conclusion - Hadoop vs HBase
Architecture Hadoop principalement basée sur HDFS et MapReduce. HBase est le composant de support du système Hadoop. HBase est capable d'héberger d'énormes tables et de fournir un accès aléatoire rapide aux données disponibles tandis que HDFS convient au stockage de fichiers volumineux. Hadoop et HBase offrent un accès rapide aux données mais avec HBase, les opérations de lecture / écriture peuvent être effectuées et pour HDFS, plusieurs lectures et une fois l'écriture peut être effectuée. Cet article décrit une compréhension de Hadoop et HBase, présente brièvement les fonctionnalités et compare judicieusement.
Article recommandé
- Apache Hadoop vs Apache Spark | Top 10 des comparaisons que vous devez savoir!
- Hadoop vs Hive - Découvrez les meilleures différences
- HBase vs Cassandra - Lequel est le meilleur (Infographie)
- Top 12 Comparaison d'Apache Hive vs Apache HBase (Infographie)
- Hadoop vs Spark: Quelles sont les fonctionnalités