
Présentation des algorithmes de réseau neuronal
- Voyons d'abord ce que signifie un réseau neuronal? Les réseaux de neurones sont inspirés par les réseaux de neurones biologiques du cerveau ou on peut dire le système nerveux. Cela a suscité beaucoup d'enthousiasme et la recherche se poursuit sur ce sous-ensemble de Machine Learning dans l'industrie.
- L'unité de calcul de base d'un réseau neuronal est un neurone ou un nœud. Il reçoit des valeurs d'autres neurones et calcule la sortie. Chaque nœud / neurone est associé au poids (w). Ce poids est donné selon l'importance relative de ce neurone ou nœud particulier.
- Donc, si nous prenons f comme fonction de nœud, alors la fonction de nœud f fournira une sortie comme indiqué ci-dessous: -
Sortie du neurone (Y) = f (w1.X1 + w2.X2 + b)
- Où w1 et w2 sont des poids, X1 et X2 sont des entrées numériques tandis que b est le biais.
- La fonction f ci-dessus est une fonction non linéaire également appelée fonction d'activation. Son objectif de base est d'introduire la non-linéarité car presque toutes les données du monde réel sont non linéaires et nous voulons que les neurones apprennent ces représentations.
Différents algorithmes de réseau neuronal
Examinons maintenant quatre algorithmes de réseaux neuronaux différents.
1. Descente en pente
Il s'agit de l'un des algorithmes d'optimisation les plus populaires dans le domaine de l'apprentissage automatique. Il est utilisé lors de la formation d'un modèle d'apprentissage automatique. En termes simples, il est essentiellement utilisé pour trouver des valeurs des coefficients qui réduisent simplement la fonction de coût autant que possible.Tout d'abord, nous commençons par définir certaines valeurs de paramètres, puis en utilisant le calcul, nous commençons à ajuster de manière itérative les valeurs afin que la fonction perdue est réduite.
Maintenant, passons à la partie qu'est-ce que le gradient?. Ainsi, un gradient signifie en grande partie que la sortie de n'importe quelle fonction changera si nous diminuons l'entrée de peu ou en d'autres termes, nous pouvons l'appeler la pente. Si la pente est abrupte, le modèle apprendra plus rapidement de la même manière qu'un modèle cesse d'apprendre lorsque la pente est nulle. En effet, c'est un algorithme de minimisation qui minimise un algorithme donné.
En dessous de la formule pour trouver la position suivante est affichée dans le cas de la descente de gradient.
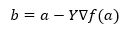
Où b est la position suivante
a est la position actuelle, le gamma est une fonction d'attente.
Ainsi, comme vous pouvez le voir, la descente en gradient est une technique très solide, mais il existe de nombreux domaines où la descente en gradient ne fonctionne pas correctement. Ci-dessous certains d'entre eux sont fournis:
- Si l'algorithme n'est pas exécuté correctement, nous pouvons rencontrer quelque chose comme le problème de la disparition du gradient. Cela se produit lorsque le gradient est trop petit ou trop grand.
- Des problèmes surviennent lorsque la disposition des données pose un problème d'optimisation non convexe. Le gradient décent ne fonctionne qu'avec des problèmes qui sont le problème optimisé convexe.
- Les ressources sont l'un des facteurs très importants à rechercher lors de l'application de cet algorithme. Si nous avons moins de mémoire allouée à l'application, nous devons éviter l'algorithme de descente de gradient.
2. La méthode de Newton
Il s'agit d'un algorithme d'optimisation de second ordre. On l'appelle un second ordre car il utilise la matrice de Hesse. Ainsi, la matrice de Hesse n'est rien d'autre qu'une matrice au carré de dérivées partielles de second ordre d'une fonction à valeurs scalaires.Dans l'algorithme d'optimisation de la méthode de Newton, elle est appliquée à la dérivée première d'une fonction f dérivable double afin qu'elle puisse trouver les racines / points fixes. Passons maintenant aux étapes requises par la méthode d'optimisation de Newton.
Il évalue d'abord l'indice de perte. Il vérifie ensuite si le critère d'arrêt est vrai ou faux. Si elle est fausse, elle calcule ensuite la direction d'entraînement de Newton et le taux d'entraînement, puis améliore les paramètres ou les poids du neurone et le même cycle continue ainsi. Vous pouvez maintenant dire qu'il faut moins d'étapes par rapport à la descente en gradient pour obtenir le minimum valeur de la fonction. Bien qu'il prenne moins d'étapes par rapport à l'algorithme de descente de gradient, il n'est pas encore largement utilisé car le calcul exact de la toile de jute et son inverse sont très coûteux en calcul.
3. Gradient conjugué
C'est une méthode qui peut être considérée comme quelque chose entre la descente de gradient et la méthode de Newton. La principale différence est qu'elle accélère la convergence lente que l'on associe généralement à la descente en gradient. Un autre fait important est qu'il peut être utilisé à la fois pour les systèmes linéaires et non linéaires et c'est un algorithme itératif.
Il a été développé par Magnus Hestenes et Eduard Stiefel. Comme déjà mentionné ci-dessus, il produit une convergence plus rapide que la descente de gradient.La raison pour laquelle il est capable de le faire est que dans l'algorithme de gradient conjugué, la recherche est effectuée avec les directions conjuguées, en raison de laquelle il converge plus rapidement que les algorithmes de descente de gradient. Un point important à noter est que γ est appelé le paramètre conjugué.
La direction d'entraînement est périodiquement réinitialisée au négatif du gradient. Cette méthode est plus efficace que la descente de gradient dans la formation du réseau neuronal car elle ne nécessite pas la matrice de Hesse qui augmente la charge de calcul et elle converge également plus rapidement que la descente de gradient. Il convient d'utiliser dans les grands réseaux de neurones.
4. Méthode Quasi-Newton
Il s'agit d'une approche alternative à la méthode de Newton, car nous savons maintenant que la méthode de Newton coûte cher en calcul. Cette méthode résout ces inconvénients dans une mesure telle qu'au lieu de calculer la matrice de Hesse et de calculer directement l'inverse, cette méthode établit une approximation pour inverser la Hesse à chaque itération de cet algorithme.
Maintenant, cette approximation est calculée en utilisant les informations de la première dérivée de la fonction de perte. Donc, nous pouvons dire que c'est probablement la méthode la mieux adaptée pour gérer les grands réseaux car elle fait gagner du temps de calcul et elle est également beaucoup plus rapide que la descente de gradient ou la méthode de gradient conjugué.
Conclusion
Avant de terminer cet article, comparons la vitesse de calcul et la mémoire pour les algorithmes mentionnés ci-dessus. Selon les besoins en mémoire, la descente de gradient nécessite le moins de mémoire et c'est aussi la plus lente. Contrairement à cela, la méthode de Newton nécessite plus de puissance de calcul. Donc, compte tenu de tout cela, la méthode Quasi-Newton est la mieux adaptée.
Articles recommandés
Cela a été un guide pour les algorithmes de réseau neuronal. Ici, nous discutons également de l'aperçu de l'algorithme de réseau neuronal avec quatre algorithmes différents respectivement. Vous pouvez également consulter nos autres articles suggérés pour en savoir plus -
- Apprentissage automatique vs réseau neuronal
- Cadres d'apprentissage automatique
- Réseaux de neurones vs apprentissage en profondeur
- K- signifie algorithme de clustering
- Guide de classification du réseau neuronal