
Introduction au cycle de vie de la science des données
Le cycle de vie de la science des données s'articule autour de l'utilisation de l'apprentissage automatique et d'autres méthodes analytiques pour produire des informations et des prévisions à partir des données afin d'atteindre un objectif commercial. L'ensemble du processus comprend plusieurs étapes telles que le nettoyage des données, la préparation, la modélisation, l'évaluation du modèle, etc. C'est un processus long qui peut prendre plusieurs mois. Il est donc très important d'avoir une structure générale à suivre pour chaque problème à portée de main. La structure mondialement reconnue dans la résolution de tout problème analytique est appelée Processus standard intersectoriel pour l'exploration de données ou cadre CRISP-DM.
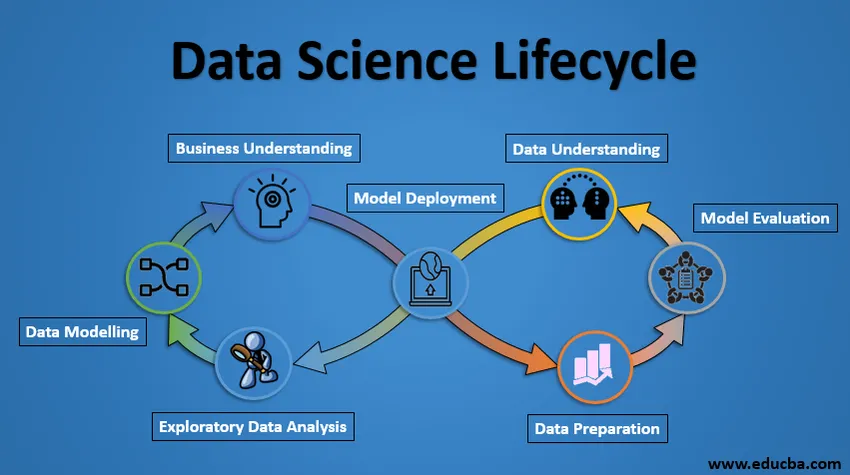
Cycle de vie de la science des données
Vous trouverez ci-dessous le projet Cycle de vie de la science des données.
1. Compréhension commerciale
L'ensemble du cycle tourne autour de l'objectif commercial. Que résolvez-vous si vous n'avez pas de problème précis? Il est extrêmement important de comprendre clairement l'objectif commercial, car ce sera votre objectif final de l'analyse. Après une bonne compréhension seulement, nous pouvons définir l'objectif spécifique d'analyse qui est en phase avec l'objectif commercial. Vous devez savoir si le client souhaite réduire la perte de crédit, ou s'il veut prédire le prix d'un produit, etc.
2. Compréhension des données
Après la compréhension de l'entreprise, la prochaine étape est la compréhension des données. Cela implique la collecte de toutes les données disponibles. Ici, vous devez travailler en étroite collaboration avec l'équipe commerciale, car elle sait réellement quelles données sont présentes, quelles données pourraient être utilisées pour ce problème commercial et d'autres informations. Cette étape consiste à décrire les données, leur structure, leur pertinence, leur type de données. Explorez les données à l'aide de graphiques. Fondamentalement, extraire toutes les informations que vous pouvez obtenir sur les données en explorant simplement les données.
3. Préparation des données
Vient ensuite l'étape de préparation des données. Cela comprend des étapes telles que la sélection des données pertinentes, l'intégration des données en fusionnant les ensembles de données, le nettoyage, le traitement des valeurs manquantes en les supprimant ou en les imputant, en traitant les données erronées en les supprimant, en vérifiant également les valeurs aberrantes en utilisant des tracés de boîte et en les manipulant . Construire de nouvelles données, dériver de nouvelles fonctionnalités à partir de celles existantes. Formatez les données dans la structure souhaitée, supprimez les colonnes et les fonctionnalités indésirables. La préparation des données est l'étape la plus longue mais sans doute l'étape la plus importante de tout le cycle de vie. Votre modèle sera aussi bon que vos données.
4. Analyse exploratoire des données
Cette étape consiste à se faire une idée de la solution et des facteurs qui l'affectent, avant de construire le modèle réel. La distribution des données au sein de différentes variables d'une entité est explorée graphiquement à l'aide de graphiques à barres, les relations entre les différentes entités sont capturées à travers des représentations graphiques telles que les diagrammes de dispersion et les cartes thermiques. De nombreuses autres techniques de visualisation des données sont largement utilisées pour explorer chaque fonctionnalité individuellement et en les combinant avec d'autres fonctionnalités.
5. Modélisation des données
La modélisation des données est au cœur de l'analyse des données. Un modèle prend les données préparées en entrée et fournit la sortie souhaitée. Cette étape comprend le choix du type de modèle approprié, qu'il s'agisse d'un problème de classification, d'un problème de régression ou d'un problème de clustering. Après avoir choisi la famille de modèles, parmi les différents algorithmes de cette famille, nous devons soigneusement choisir les algorithmes pour les implémenter et les implémenter. Nous devons régler les hyperparamètres de chaque modèle pour atteindre les performances souhaitées. Nous devons également nous assurer qu'il existe un juste équilibre entre les performances et la généralisation. Nous ne voulons pas que le modèle apprenne les données et fonctionne mal sur les nouvelles données.
6. Évaluation du modèle
Ici, le modèle est évalué pour vérifier s'il est prêt à être déployé. Le modèle est testé sur des données invisibles, évalué sur un ensemble de métriques d'évaluation soigneusement pensées. Nous devons également nous assurer que le modèle est conforme à la réalité. Si nous n'obtenons pas un résultat satisfaisant dans l'évaluation, nous devons réitérer l'ensemble du processus de modélisation jusqu'à ce que le niveau de métrique souhaité soit atteint. Toute solution de science des données, un modèle d'apprentissage automatique, tout comme un humain, devrait évoluer, devrait pouvoir s'améliorer avec de nouvelles données, s'adapter à une nouvelle métrique d'évaluation. Nous pouvons construire plusieurs modèles pour un certain phénomène, mais beaucoup d'entre eux peuvent être imparfaits. L'évaluation des modèles nous aide à choisir et à construire un modèle parfait.
7. Déploiement du modèle
Le modèle après une évaluation rigoureuse est finalement déployé dans le format et le canal souhaités. Il s'agit de la dernière étape du cycle de vie de la science des données. Chaque étape du cycle de vie de la science des données expliquée ci-dessus doit être soigneusement étudiée. Si une étape n'est pas exécutée correctement, cela affectera par conséquent l'étape suivante et tout l'effort sera gaspillé. Par exemple, si les données ne sont pas collectées correctement, vous perdrez des informations et vous ne construirez pas un modèle parfait. Si les données ne sont pas nettoyées correctement, le modèle ne fonctionnera pas. Si le modèle n'est pas évalué correctement, il échouera dans le monde réel. Dès la compréhension de l'entreprise jusqu'au déploiement du modèle, chaque étape doit recevoir l'attention, le temps et les efforts appropriés.
Articles recommandés
Ceci est un guide du cycle de vie de la science des données. Nous discutons ici d'un aperçu du cycle de vie de la science des données et des étapes qui composent un cycle de vie de la science des données. Vous pouvez également consulter nos articles connexes pour en savoir plus -
- Introduction aux algorithmes de science des données
- Science des données vs génie logiciel | Top 8 des comparaisons utiles
- Différents types de techniques de science des données
- Compétences en science des données avec types