

Différence entre Apache Hive et Apache HBase -
L'histoire d'Apache Hive commence en 2007, lorsque le programmeur non Java doit lutter pour utiliser Hadoop MapReduce. Les chercheurs et les développeurs ont prédit que demain serait une ère de Big Data. Déjà différents formats de données comme structurés, semi-structurés et non structurés s'accumulaient. Même Facebook se débattait avec la plus grande quantité de traitement de données. Les chercheurs de Facebook ont présenté Apache Hive pour le traitement des données sur le cluster Hadoop. Facebook a été la première entreprise à proposer Apache Hive.
L'histoire d'Apache HBase commence en 2006 lorsque la startup Powerset basée à San Francisco essayait de construire un moteur de recherche en langage naturel pour le Web. HBase est une implémentation de la Bigtable de Google. Avons-nous jamais réalisé pourquoi il était nécessaire de proposer une autre architecture de stockage? Le système de gestion de base de données relationnelle existe depuis le début des années 1970. Il existe de nombreux cas d'utilisation pour lesquels les bases de données relationnelles sont parfaitement logiques, mais pour certains problèmes spécifiques, le modèle relationnel ne convient pas très bien.
Permettez-moi de vous expliquer plus en détail Apache Hive et Apache HBase.
Différences entre Apache Hive et Apache HBase
Apache Hive est un projet open source Apache construit au-dessus de Hadoop pour interroger, résumer et analyser de grands ensembles de données à l'aide d'une interface de type SQL. Apache Hive fournit un langage de type SQL appelé HiveQL, qui convertit de manière transparente les requêtes en MapReduce pour exécution sur de grands ensembles de données stockés dans Hadoop Distributed File System (HDFS). Apache Hive est un composant de cluster Hadoop qui est normalement déployé par les analystes de données. La ruche Apache est utilisée pour le traitement par lots de gros travaux ETL. Apache Hive prend également en charge les requêtes SQL par lots sur de très grands ensembles de données. Apache Hive augmente la flexibilité de conception du schéma ainsi que la sérialisation et la désérialisation des données. Apache Hive ne prend pas en charge le traitement des transactions en ligne (OLTP) car la ruche ne prend pas en charge les requêtes en temps réel et les mises à jour au niveau des lignes.
Apache HBase est une base de données NoSQL open source qui fournit un accès en temps réel, en lecture et en écriture à de grands ensembles de données. NoSQL est une base de données non relationnelle. Apache HBase est une base de données orientée colonne distribuée qui s'exécute sur Hadoop Distributed File System (HDFS). Ainsi, HBase apporte les avantages de NoSQL à Hadoop. Apache HBase offre des capacités d'accès aléatoire aux données présentes dans HDFS. Il exploite la tolérance aux pannes fournie par le HDFS. L'utilisateur peut stocker les données dans HDFS soit directement, soit via HBase.
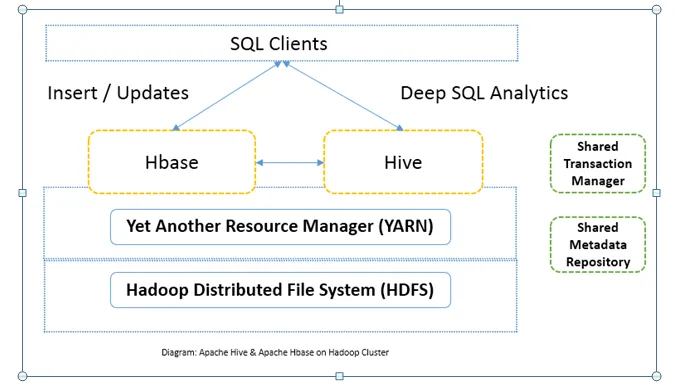
Comparaison directe entre Apache Hive et Apache HBase (infographie)
Ci-dessous se trouve la principale différence entre Apache Hive et Apache HBase

Différences clés - Apache Hive vs Apache HBase
Voici la liste des points, décrivez les principales différences entre Apache Hive et Apache HBase:
- Apache HBase est une base de données tandis qu'Apache Hive est un moteur de base de données.
- Apache Hive est principalement utilisé pour le traitement par lots (OLAP) tandis qu'Apache HBase est principalement utilisé pour le traitement transactionnel (OLTP).
- Apache Hive exécute la plupart des requêtes SQL tandis qu'Apache HBase n'autorise pas directement les requêtes SQL.
- Apache Hive ne prend pas en charge les opérations de niveau enregistrement telles que la mise à jour, l'insertion et la suppression tandis qu'Apache HBase prend en charge les opérations de niveau d'enregistrement telles que la mise à jour, l'insertion et la suppression.
- Apache Hive s'exécute sur MapReduce tandis qu'Apache HBase s'exécute sur Hadoop Distributed File System (HDFS).
Apache Hive interroge les fichiers en définissant une table virtuelle et en exécutant des requêtes HQL dessus. C'est un processus où les fichiers sont virtuellement connectés à une table comme une structure et l'utilisateur peut exécuter Hive Query Language (HQL) et ces requêtes sont converties en MapReduce Job par Hive. L'utilisateur n'a pas à écrire le travail MapReduce, les requêtes HQL sont converties en interne en fichiers jar et ces fichiers jar seront implémentés sur des jeux de données.
Dans Apache HBase, les tables sont divisées en régions et sont desservies par les serveurs de région. D'autres régions sont divisées verticalement par familles de colonnes en magasins et les magasins sont enregistrés en tant que fichiers dans HDFS.
Quand utiliser Apache Hive:
- Exigences d'entreposage de données
- Requêtes analytiques
- Analyse des données qui connaissent SQL
Quand utiliser Apache HBase:
- Traitement des données rapide et interactif
- Requêtes en temps réel
- Recherches rapides
- Traitement côté serveur
- Accès en lecture / écriture aléatoire aux Big Data
- Évolutivité des applications
Apache Hive peut être utilisé pour calculer les tendances et les journaux du site Web de commerce électronique pour une durée, une région ou un fuseau horaire particulier. Il peut être utilisé pour traiter des requêtes par lots sur des données historiques, tandis qu'Apache HBase peut être utilisé par Facebook ou LinkedIn pour la messagerie et l'analyse en temps réel. Il peut également être utilisé pour compter les likes.
Tableau de comparaison Apache Hive vs Apache HBase
Je discute des principaux artefacts et je fais la distinction entre Apache Hive et Apache HBase.
| Apache Hive | Apache HBase | |
| Traitement de l'information | Apache Hive est utilisé pour
traitement par lots, c'est-à-dire traitement analytique en ligne (OLAP) | Apache HBase est utilisé pour le traitement transactionnel, c'est-à-dire le traitement transactionnel en ligne (OLTP) |
| Vitesse de traitement | Apache Hive a une latence plus élevée en raison de l'exécution du travail MapReduce en arrière-plan | Apache HBase fonctionne sur les requêtes en temps réel et beaucoup plus rapidement qu'Apache Hive |
| Compatibilité avec Hadoop | Apache Hive s'exécute au-dessus de MapReduce | Apache HBase s'exécute sur HDFS |
| Définition | Apache Hive est open source et similaire à SQL utilisé pour les requêtes analytiques | Apache HBase est une base de données NoSQL open source utilisée pour les requêtes en temps réel |
| Métadonnées partagées | Les données créées dans Apache Hive sont automatiquement visibles pour Apache HBase | Les données créées dans Apache HBase sont automatiquement visibles pour Apache Hive |
| Schéma | Apache hive prend en charge le schéma pour l'insertion de données dans des tableaux | Apache HBase est une base de données sans schéma. |
| Fonction de mise à jour | La fonctionnalité de mise à jour est compliquée dans Apache Hive | L'utilisateur peut très facilement mettre à jour les données dans Apache HBase |
| Les opérations | Les opérations dans Apache Hive ne s'exécutent pas en temps réel | Les opérations dans Apache HBase s'exécutent en temps réel |
| Types de données | Apache Hive est destiné aux données structurées et semi-structurées | Apache HBase est destiné aux données non structurées. |
| Niveau de cohérence | La ruche Apache prend en charge la cohérence éventuelle | Apache HBase prend en charge la cohérence immédiate |
| Méthodes de partition | Apache Hive prend en charge les fonctionnalités de partage | Apache HBase prend également en charge les fonctionnalités de partage |
| Stockage de données | La date est stockée dans Hive Metastore, Partitions and Buckets dans Apache Hive | Les données sont stockées dans les colonnes et les lignes des tables dans Apache HBase |
Conclusion - Apache Hive vs Apache HBase
Généralement, Apache Hive vs Apache HBase est utilisé ensemble dans le même cluster. Les deux peuvent être utilisés ensemble pour améliorer la puissance de traitement. Depuis hive améliore les côtés analytiques de HDFS tandis que HBase améliore les transactions en temps réel. L'utilisateur peut utiliser Hive comme un outil ETL pour les insertions par lots avec les données dans HBase, puis pour exécuter des requêtes qui peuvent encore joindre les données présentes sur les tables HBase avec les données déjà présentes sur HDFS. Les données peuvent être lues et écrites depuis Apache Hive vers HBase et vice versa. L'interface entre Apache Hive et Apache HBase est encore en phase de maturation. Il y a encore beaucoup à venir. Pourtant, je peux dire que les deux Apache Hive vs Apache HBase rendent le cluster Hadoop plus robuste et plus puissant.
Articles Liés:
Ceci a été un guide pour Apache Hive vs Apache HBase, leur signification, comparaison tête à tête, différences clés, tableau de comparaison et conclusion. Vous pouvez également consulter les articles suivants pour en savoir plus -
- Top 5 des tendances Big Data
- 5 défis de l'analyse de Big Data
- Comment cracker l'interview du développeur Hadoop?
- 5 défis de l'analyse de Big Data