

Différence entre Big Data et Apache Hadoop
Tout est sur Internet. Internet a beaucoup de données. Par conséquent, tout est Big Data. Savez-vous que 2, 5 Quintillion Bytes Data sont créés chaque jour et s'accumulent sous forme de Big Data? Nos activités quotidiennes comme les commentaires, les likes, les publications, etc. sur les réseaux sociaux comme Facebook, LinkedIn, Twitter et Instagram s'ajoutent en tant que Big Data. On suppose que d'ici 2020, près de 1, 7 mégaoctets de données seront créés chaque seconde, pour chaque personne sur terre. Vous pouvez imaginer et considérer la quantité de données générées en supposant que chaque personne sur terre. Aujourd'hui, nous sommes connectés et partageons nos vies en ligne. La plupart d'entre nous sont connectés en ligne. Nous vivons dans une maison intelligente et utilisons des véhicules intelligents et tous sont connectés à nos téléphones intelligents. Avez-vous déjà imaginé comment ces appareils deviennent intelligents? Je voudrais vous donner une réponse très simple, c'est en raison de l'analyse de la très grande quantité de données, à savoir le Big Data. D'ici cinq ans, il y aura plus de 50 milliards d'appareils connectés intelligents dans le monde, tous développés pour collecter, analyser et partager des données afin de rendre notre vie plus confortable.
Ce qui suit sont les introductions de Big Data vs Apache Hadoop
Présentation du terme Big Data
Qu'est-ce que le Big Data? Quelle taille de données est considérée comme volumineuse et sera appelée Big Data? Nous avons de nombreuses hypothèses relatives au terme Big Data. Il est possible que la quantité de données dise que 50 téraoctets puissent être considérés comme des mégadonnées pour les startups, mais il ne peut pas s'agir de mégadonnées pour des entreprises comme Google et Facebook. C'est parce qu'ils ont l'infrastructure pour stocker et traiter cette quantité de données. Je voudrais définir le terme Big Data comme:
- Le Big Data est la quantité de données juste au-delà de la capacité de la technologie à stocker, gérer et traiter efficacement.
- Les mégadonnées sont des données dont l'échelle, la diversité et la complexité nécessitent une nouvelle architecture, des techniques, des algorithmes et des analyses pour les gérer et en extraire de la valeur et des connaissances cachées.
- Les mégadonnées sont des actifs d'information à volume élevé, à grande vitesse et à grande variété qui nécessitent des formes rentables et innovantes de traitement de l'information qui améliorent la compréhension, la prise de décision et l'automatisation des processus.
- Les mégadonnées désignent les technologies et les initiatives qui impliquent des données trop diverses, en évolution rapide ou massives pour que les technologies, les compétences et les infrastructures conventionnelles puissent être traitées efficacement. Autrement dit, le volume, la vitesse ou la variété des données est trop important.
3 V de Big Data
- Volume: Le volume fait référence à la quantité / quantité à laquelle les données sont créées, comme Toutes les heures, les transactions des clients de Wal-Mart fournissent à l'entreprise environ 2, 5 pétaoctets de données.
- Velocity: Velocity fait référence à la vitesse à laquelle les données se déplacent, comme les utilisateurs de Facebook envoient en moyenne 31, 25 millions de messages et visionnent 2, 77 millions de vidéos par minute chaque jour sur Internet.
- Variété: la variété fait référence à différents formats de données créés comme des données structurées, semi-structurées et non structurées. Tout comme l'envoi de courriels avec la pièce jointe sur Gmail, ce sont des données non structurées, tandis que la publication de commentaires avec certains liens externes est également appelée données non structurées. Le partage d'images, de clips audio et de clips vidéo est une forme de données non structurée.
Stocker et traiter cet énorme volume, vitesse et variété de données est un gros problème. Nous devons penser à une autre technologie que le SGBDR pour le Big Data. En effet, le SGBDR est capable de stocker et de traiter uniquement des données structurées. Voici donc Apache Hadoop vient comme un sauvetage.
Présentation de Term Apache Hadoop
Apache Hadoop est un cadre logiciel open source pour le stockage de données et l'exécution d'applications sur des clusters de matériel de base. Apache Hadoop est un cadre logiciel qui permet le traitement distribué d'ensembles de données volumineux sur des grappes d'ordinateurs à l'aide de modèles de programmation simples. Il est conçu pour passer de serveurs uniques à des milliers de machines, chacune offrant un calcul et un stockage locaux. Apache Hadoop est un framework pour le stockage ainsi que le traitement des Big Data. Apache Hadoop est capable de stocker et de traiter tous les formats de données comme les données structurées, semi-structurées et non structurées. Apache Hadoop est un matériel open source et de base qui a révolutionné l'industrie informatique. Il est facilement accessible à tous les niveaux des entreprises. Ils n'ont pas besoin d'investir davantage pour configurer le cluster Hadoop et sur différentes infrastructures. Voyons donc en détail la différence utile entre Big Data et Apache Hadoop dans cet article.
Framework Apache Hadoop
Le framework Apache Hadoop est divisé en deux parties:
- Hadoop Distributed File System (HDFS): cette couche est responsable du stockage des données.
- MapReduce: cette couche est responsable du traitement des données sur le cluster Hadoop.
Hadoop Framework est divisé en architecture maître et esclave. Couche Hadoop Distributed File System (HDFS) Nom Le nœud est le composant maître tandis que le nœud de données est le composant esclave tandis que dans la couche MapReduce Job Tracker est le composant maître tandis que le suivi des tâches est le composant esclave. Voici le schéma du framework Apache Hadoop.
Pourquoi Apache Hadoop est-il important?
- Capacité de stocker et de traiter d'énormes quantités de tout type de données, rapidement
- Puissance de calcul: le modèle informatique distribué de Hadoop traite rapidement les mégadonnées. Plus vous utilisez de nœuds de calcul, plus vous disposez de puissance de traitement.
- Tolérance aux pannes: le traitement des données et des applications est protégé contre les pannes matérielles. Si un nœud tombe en panne, les travaux sont automatiquement redirigés vers d'autres nœuds pour s'assurer que l'informatique distribuée n'échoue pas. Plusieurs copies de toutes les données sont stockées automatiquement.
- Flexibilité: vous pouvez stocker autant de données que vous le souhaitez et décider comment les utiliser ultérieurement. Cela inclut les données non structurées comme le texte, les images et les vidéos.
- Faible coût: le framework open-source est gratuit et utilise du matériel de base pour stocker de grandes quantités de données.
- Évolutivité: vous pouvez facilement développer votre système pour gérer plus de données simplement en ajoutant des nœuds. Peu d'administration est requise
Comparaison directe entre Big Data et Apache Hadoop (infographie)
Vous trouverez ci-dessous le top 4 de la comparaison entre le Big Data et Apache Hadoop
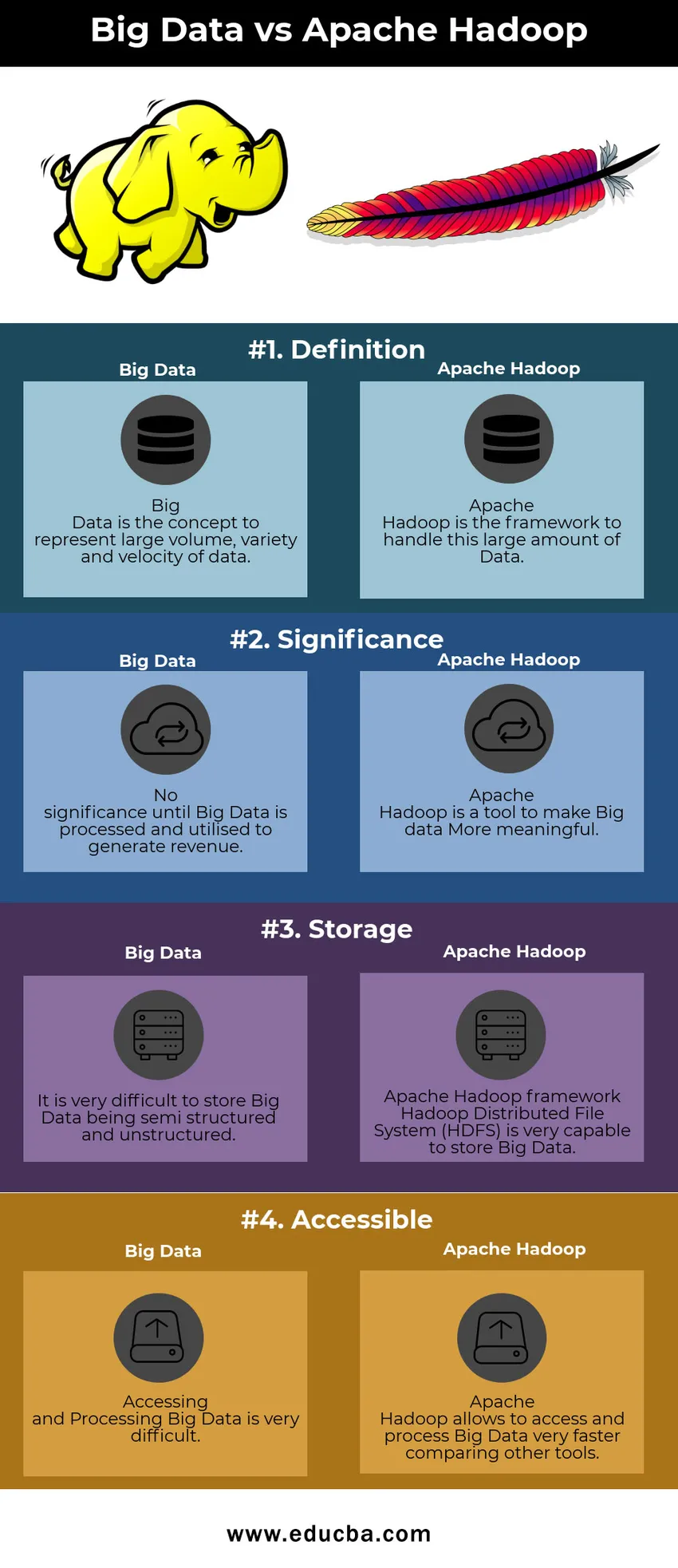
Comparaison Big Data vs Apache Hadoop
Je discute des principaux artefacts et fais la distinction entre Big Data et Apache Hadoop
| Big Data | Apache Hadoop | |
| Définition | Le Big Data est le concept pour représenter un grand volume, une grande variété et une grande vitesse de données | Apache Hadoop est le cadre pour gérer cette grande quantité de données |
| Importance | Aucune importance tant que le Big Data n'est pas traité et utilisé pour générer des revenus | Apache Hadoop est un outil pour rendre le Big Data plus significatif |
| Espace de rangement | Il est très difficile de stocker des Big Data semi-structurés et non structurés | Cadre Apache Hadoop Hadoop Distributed File System (HDFS) est très capable de stocker des Big Data |
| Accessible | Accéder et traiter les Big Data est très difficile | Apache Hadoop permet d'accéder et de traiter les Big Data très rapidement en comparant d'autres outils |
Conclusion - Big Data vs Apache Hadoop
Vous ne pouvez pas comparer le Big Data et Apache Hadoop. C'est parce que le Big Data est un problème alors qu'Apache Hadoop est une solution. Étant donné que la quantité de données augmente de façon exponentielle dans tous les secteurs, il est donc très difficile de stocker et de traiter des données à partir d'un seul système. Donc, pour traiter cette grande quantité de données, nous avons besoin d'un traitement et d'un stockage distribués des données. Par conséquent, Apache Hadoop propose la solution de stockage et de traitement d'une très grande quantité de données. Enfin, je conclurai que le Big Data est une grande quantité de données complexes tandis qu'Apache Hadoop est un mécanisme pour stocker et traiter le Big Data de manière très efficace et fluide.
Article recommandé
Cela a été un guide pour Big Data vs Apache Hadoop, leur signification, leur comparaison directe, leurs principales différences, leur tableau de comparaison et leur conclusion. cet article contient toutes les différences utiles entre Big Data et Apache Hadoop. Vous pouvez également consulter les articles suivants pour en savoir plus -
- Big Data vs Data Science - En quoi sont-ils différents?
- Top 5 des tendances Big Data que les entreprises devront maîtriser
- Hadoop vs Apache Spark - Choses intéressantes que vous devez savoir
- Apache Hadoop vs Apache Spark | Top 10 des comparaisons que vous devez savoir!