
Différence entre Hive et HBase
Apache Hive et HBase sont des technologies de Big Data basées sur Hadoop. Ils avaient tous les deux l'habitude d'interroger des données. Hive et HBase fonctionnent sur Hadoop et diffèrent dans leurs fonctionnalités. Hive est un dialecte SQL basé sur la réduction de carte tandis que HBase ne prend en charge que MapReduce. HBase stocke les données sous forme de paires de familles clé / valeur ou colonne alors que Hive ne stocke pas de données.
Différences face à face entre Hive vs HBase (Infographie)
Vous trouverez ci-dessous la différence entre les 8 principaux Hive vs HBase
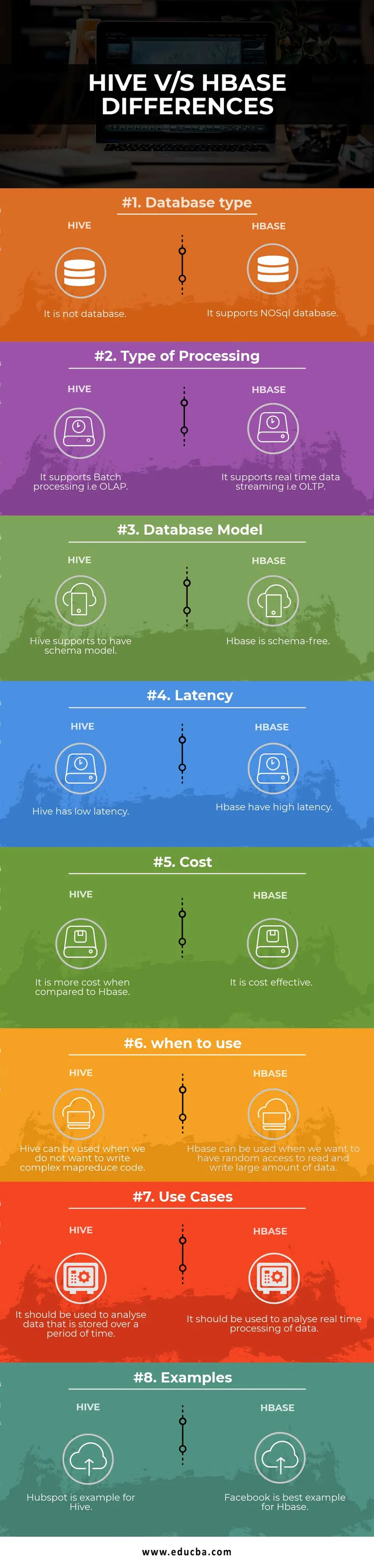
Différences clés entre Hive et HBase
- Hbase est conforme à ACID alors que Hive ne l'est pas.
- Hive prend en charge le partitionnement et les critères de filtrage basés sur le format de date tandis que HBase prend en charge le partitionnement automatisé.
- Hive ne prend pas en charge les instructions de mise à jour tandis que HBase les prend en charge.
- Hbase est plus rapide que Hive dans la récupération des données.
- Hive est utilisé pour traiter des données structurées tandis que HBase, car il est sans schéma, peut traiter tout type de données.
- Hbase est hautement (horizontalement) évolutif par rapport à Hive.
- Hive analyse les données sur le HDFS avec le support de SQL Queries, puis les convertit en une carte et réduit les travaux tandis que dans Hbase, car il s'agit d'un streaming en temps réel, il effectue directement ses opérations sur la base de données en partitionnant les tables et les familles de colonnes.
- lors de l'interrogation des données, la ruche utilise un shell appelé Hive shell pour émettre les commandes tandis que HBase étant donné qu'il s'agit d'une base de données, nous utiliserons une commande pour traiter les données dans HBase.
- Pour accéder au shell Hive, nous utiliserons la commande hive. Après avoir donné cela, il apparaîtra comme ruche>. Dans HBase, nous donnons simplement comme Use HBase.
Tableau de comparaison Hive vs HBase
| Base de comparaison | Ruche | Hbase |
| Type de base de données | Ce n'est pas une base de données | Il prend en charge la base de données NoSQL |
| Type de traitement | Il prend en charge le traitement par lots, c'est-à-dire OLAP | Il prend en charge le streaming de données en temps réel, c'est-à-dire OLTP |
| Modèle de base de données | Hive prend en charge un modèle de schéma | Hbase est sans schéma |
| Latence | La ruche a une faible latence | Hbase a une latence élevée |
| Coût | Il est plus coûteux que HBase | C'est rentable |
| quand utiliser | Hive peut être utilisé lorsque nous ne voulons pas écrire de code MapReduce complexe | HBase peut être utilisé lorsque nous voulons avoir un accès aléatoire pour lire et écrire une grande quantité de données |
| Cas d'utilisation | Il doit être utilisé pour analyser les données stockées sur une période de temps | Il doit être utilisé pour analyser le traitement en temps réel des données. |
| Exemples | Hubspot est un exemple pour Hive | Facebook est le meilleur exemple pour Hbase |
Différences de codage entre Hive vs HBase
Voyons maintenant les différences fondamentales entre Hive et HBase dans le codage.
| Base de comparaison | Ruche | Hbase |
| Pour créer une base de données | CRÉER UNE BASE DE DONNÉES (S'IL N'EXISTE PAS) NOM DE LA BASE DE DONNÉES; | Étant donné que Hbase est une base de données, nous n'avons pas besoin de créer une base de données spécifique |
| Pour supprimer une base de données | DROP DATABASE (SI EXISTE) NOM DE LA BASE DE DONNÉES (RESTRICT OU CASCADE); | N / A |
| Pour créer une table | CRÉER UN TABLEAU (TEMPORAIRE OU EXTERNE) (SI IL N'EXISTE PAS) ((nom de colonne type_données (commentaire colonne-commentaire), ….)) (commentaire table_comment) (format de ligne ROW FORMAT) (stocké au format fichier) | CRÉER '', '' |
| Pour modifier une table | ALTER TABLE nom RENAME TO nouveau-nom
ALTER TABLE name DROP (COLUMN) nom-colonne ALTER TABLE name ADD COLUMNS (col-spec (, col-spec ..)) ALTER TABLE nom CHANGE nom-colonne nouveau-nom nouveau-type ALTER TABLE name REMPLACER LES COLONNES (col-spec (, col-spec ..)) | ALTER 'TABLE-NAME', NAME => 'COLUMN-NAME', VERSIONS => |
| Désactiver une table | N / A | désactiver 'TABLE-NAME' -> pour désactiver le nom de table spécifié
disable_all 'r *' -> pour désactiver toutes les tables qui correspondent à l'expression régulière |
| Activation d'une table | N / A | activer «NOM DE TABLE» |
| Pour supprimer une table | DROP TABLE IF EXISTS nom-table | Si nous voulons supprimer une table, nous devons d'abord la désactiver
désactiver 'nom-table' drop 'nom-table' De même, nous pouvons utiliser disable_all et drop_all pour supprimer les tables qui correspondent à l'expression régulière spécifiée. |
| Pour répertorier les bases de données | afficher les bases de données; | N / A |
| Pour répertorier les tables dans la base de données | montrer des tables; | liste |
| Pour décrire le schéma d'une table | décrire le nom de la table; | décrire «nom-table» |
Intégration de Hive vs HBase
- Installez et configurez Hive.
- Installez et configurez HBase.
- Pour l'intégration de Hive et HBase, nous utilisons STORAGE HANDLERS dans Hive.
- Les gestionnaires de stockage sont une combinaison de SERDE, InputFormat et OutputFormat qui accepte toute entité externe en tant que table dans Hive.
- Cette fonctionnalité permet donc à un utilisateur d'émettre des requêtes SQL, que ce soit la table présente dans Hadoop ou dans la base de données NOSQL telle que HBase, MongoDB, Cassandra, Amazon DynamoDB.
- Nous allons maintenant examiner un exemple de connexion de Hive à HBase à l'aide de HiveStorageHandler:
- Tout d'abord, nous devons créer une table Hbase à l'aide de la commande.
créer 'Student', 'personalinfo', 'dept info'
-> Personalinfo et dept info créent deux familles de colonnes différentes dans la table Student.
- Nous devons insérer des données dans la table Student, par exemple, comme indiqué ci-dessous.
mettre «étudiant», «sid01», «info personnelle: nom», «Ram»
mettre 'étudiant', 'sid01', 'personalinfo: mailid', ' '
mettez 'étudiant', 'sid01', 'deptinfo: nom dept', 'Java'
mettez 'Student', 'sid01 ′, ' deptinfo: joinyear ', ' 1994 ′
-> De même, nous pouvons créer des données pour sid02, sid03…
- Nous devons maintenant créer une table Hive pointant vers la table HBase.
- Pour chaque colonne de l'Hbase, nous créerons une table particulière pour cette colonne dans Hive.Dans ce cas, nous créerons 2 tables dans Hive
create external table student_hbase(sid String, name String, mailid String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler with serdeproperties("hbase.columns.mapping"=":key, personalinfo:name, personalinfo:mailid")
tblproperties("hbase.table.name"="student");
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
-> De même, nous devons créer un tableau de détails sur les informations de rayon dans la ruche.
- Maintenant, nous pouvons écrire une requête SQL dans une ruche comme mentionné ci-dessous.
select * from student_hbase;
De cette façon, nous pouvons intégrer Hive à HBase.
Conclusion - Hive vs HBase
Comme discuté, ce sont deux technologies différentes qui fournissent différentes fonctionnalités où Hive fonctionne en utilisant le langage SQL et il peut également être appelé car HQL et HBase utilisent des paires clé-valeur pour analyser les données. Hive et HBase fonctionnent mieux s'ils sont combinés car Hive a une faible latence et peut traiter une énorme quantité de données mais ne peut pas maintenir des données à jour et HBase ne prend pas en charge l'analyse des données mais prend en charge les mises à jour au niveau des lignes sur une grande quantité des données.
Article recommandé
Ceci a été un guide pour Hive vs HBase, leur signification, leur comparaison directe, leurs principales différences, leur tableau de comparaison et leur conclusion. Vous pouvez également consulter les articles suivants pour en savoir plus -
- Apache Pig vs Apache Hive - 12 principales différences utiles
- Découvrez les 7 meilleures différences entre Hadoop et HBase
- Top 12 Comparaison d'Apache Hive vs Apache HBase (Infographie)
- Hadoop vs Hive - Découvrez les meilleures différences