

Comment installer Apache
Avant d'entrer dans la façon d'installer la partie Apache, nous aurions d'abord un aperçu général d'Apache et de son utilisation en science des données.
Qu'est-ce qu'Apache?

Apache Web Server est un serveur HTTP qui présente des sites Web aux visiteurs qui viennent sur votre serveur. Donc, si vous souhaitez déployer un site Web pour une entreprise ou votre organisation, vous utiliserez probablement Apache pour cela.
Il existe d'autres serveurs HTTP, comme IIS, mais Apache est la norme que la plupart des gens utilisent, qu'ils soient sous Linux, Windows ou Mac. Apache est la valeur par défaut que la plupart des gens utilisent, car elle est bien connue, très fiable et gratuite.
Cependant, une chose à réaliser avec Apache est que, comme il s'agit d'un serveur HTTP, donc si vous l'installez sur Linux ou Windows ou Mac, tout ce qu'il vous permettrait de faire est de présenter des sites Web statiques aux visiteurs qui viennent sur votre serveur. Par conséquent, si vous codez un site Web HTML sans autre langage de programmation que JavaScript, vous pouvez l'utiliser avec un serveur Apache uniquement. Vous pouvez brancher toutes vos balises sur le serveur Apache et les présenter à vos visiteurs.
Comment Apache a-t-il utilisé en Data Science?
La science des données est le domaine d'études le plus demandé dans le monde moderne. Le Data Scientist est considéré comme le travail le plus sexy du 21ème siècle avec des professionnels de différentes disciplines qui veulent apprendre et devenir Data Scientist. Apache joue un rôle crucial dans tout passionné de science des données, car ils ont besoin d'une connaissance suffisante de l'écosystème Apache Hadoop.
Écosystème Apache Hadoop
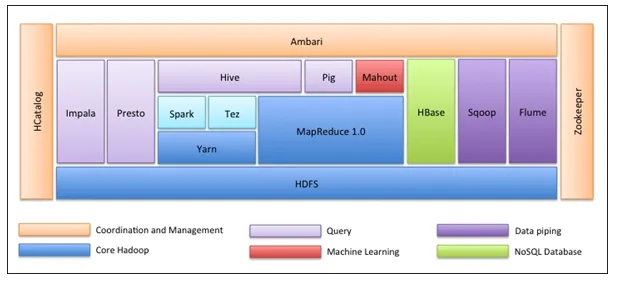
La toute première chose est que l'écosystème Hadoop n'est pas un outil. Ce n'est pas un langage de programmation ou un cadre unique. Il s'agit d'un groupe d'outils qui sont utilisés ensemble par diverses sociétés dans différents domaines pour de multiples tâches. Nous allons passer en revue chaque outil un par un ci-dessous: -
- Apache HDFS (Hadoop Distributed File System) est l'unité de stockage de Hadoop qui pouvait stocker des données structurées, semi-structurées et non structurées. HDFS contient des métadonnées qui conservent le fichier journal sur les données stockées. Il a deux composants - NameNode et DataNode.
- Apache Yarn est le négociateur de ressources qui effectue toutes les activités de traitement comme la planification des tâches, l'allocation des ressources, etc. Il a deux services - Le premier est le gestionnaire de ressources qui planifie les applications s'exécutant sur Yarn. Le deuxième est le Node Manager qui surveille l'utilisation des ressources .
- Apache Map Reduce est le composant de traitement de données de Hadoop qui traite de grands ensembles de données à l'aide de l'informatique distribuée et parallèle basée sur les fonctions Map, Sort et Shuffle et Reduce. La fonction Carte filtre les données, puis le tri et le brassage sont effectués et, à la fin, la fonction Réduire agrège et résume le résultat.
- Apache Pig utilisé principalement dans ETL. Il comprend deux parties - Pig Latin et le runtime Pig. Pig Latin est la langue utilisée pour le traitement des données à l'aide d'une requête, tandis que Pig runtime est l'environnement d'exécution. Une ligne de Pig Latin équivaut presque à 100 lignes de code Map Reduce. Le processus consiste d'abord à charger les données, puis à les regrouper, les trier, les filtrer et les stocker dans HDFS.
- Apache Hive utilise une requête de type SQL pour analyser les données dans un environnement distribué. Il a deux composants - la ligne de commande Hive et le serveur JDBC / ODBC et le langage utilisé est appelé HiveQL.
- Apache Mahout est la bibliothèque d'apprentissage machine écrite en Java et utilisée pour créer des applications d'apprentissage machine telles que le clustering, la classification ou la régression. Il a différents algorithmes intégrés pour différents cas d'utilisation.
- Apache HBase est une base de données NoSQL écrite en Java qui s'exécute sur Hadoop. Il est construit sur la base de BigTable de Google et est capable de gérer tous les types de données.
- Apache Sqoop est l'un des outils d'ingestion de données qui est utilisé pour le transfert de données structurées en bloc entre RDBMS et Hadoop.
- Apache Flume est un autre outil d'intégration de données utilisé pour le transfert de données semi-structuré et non structuré entre Hadoop et d'autres sources de données.
- ZooKeeper est le coordinateur qui assure la coordination entre les différents outils de l'écosystème Hadoop.
- Apache Ambari est un gestionnaire de cluster qui provisionne, gère les clusters Hadoop et surveille également leur état de santé et leur état.
- Apache Tez est un nouvel outil dans l'écosystème Hadoop qui accélère le traitement des requêtes de Hadoop.
- Apache Presto est un moteur de requête SQL distribué et open source qui permet une capacité de requête multiplateforme.
- Apache HCatalog est un système de gestion des métadonnées et des tables pour Hadoop qui permet l'interopérabilité entre les outils de traitement des données. Il aide également les utilisateurs à choisir les meilleurs outils pour leurs environnements.
- Apache Spark est le framework le plus utilisé et le plus populaire parmi les Data Scientist. Il s'agit d'un système informatique en grappe à haute vitesse qui optimise l'utilisation des ressources en cas de nombreuses tâches itératives. Il offre une flexibilité pour le traitement par lots et l'analyse des données en temps réel.
Voici les étapes pour installer Apache
Jusqu'à présent, nous avons découvert Apache et son utilité pour quiconque souhaite apprendre la Data Science ou le Big Data Analytics. Maintenant, nous allons plonger et installer apache sur Windows en fonction des étapes ci-dessous.
- Allez sur https://httpd.apache.org/ et cliquez sur le lien Télécharger sous Apache httpd 2.4.38 Released section.

- Il vous amènera à la page suivante, puis cliquez sur Fichiers pour Microsoft Windows.
- Cliquez sur Apache Lounge.

- Vous pouvez télécharger 32 ou 64 bits du fichier zip en fonction de votre système d'exploitation Windows. Nous allons télécharger la version 64 bits ici. Cliquez sur le lien .zip correspondant pour télécharger.

- Maintenant, il nécessite Visual Studio 2017 redistribuable C ++. Nous allons donc le télécharger à partir du lien 32 bits ou 64 bits correspondant

- Une fois les deux fichiers téléchargés, nous irons à l'emplacement téléchargé et installerons d'abord Visual Studio 2017 redistribuable C ++. Double-cliquez sur le fichier .exe.

- Cochez «J'accepte» et cliquez sur Installer.

- L'installation d'Apache est en cours.
- Une fois terminé, vous obtiendrez un message comme celui-ci. Cliquez sur Fermer pour terminer l'installation.
- Maintenant, allez dans le dossier où vous téléchargez le fichier zip Apache. Faites un clic droit dessus et sélectionnez extraire ici.
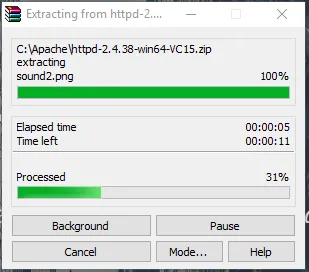
- Maintenant, nous aurons un dossier Apache24 créé. Copiez ce dossier sur le lecteur C, puis nous ajouterons un chemin d'accès aux variables d'environnement système.
Allez dans Propriétés système -> onglet Avancé -> Cliquez sur le bouton Variables d'environnement ci-dessous.
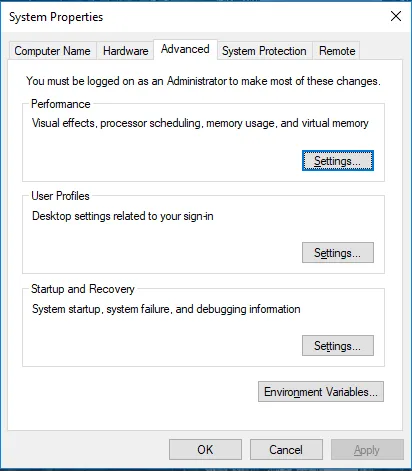
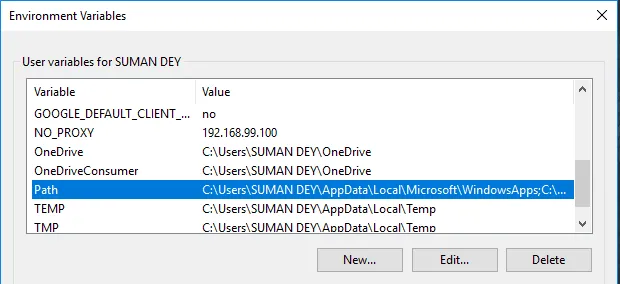
- Dans Variables, recherchez Path et cliquez sur Edit.
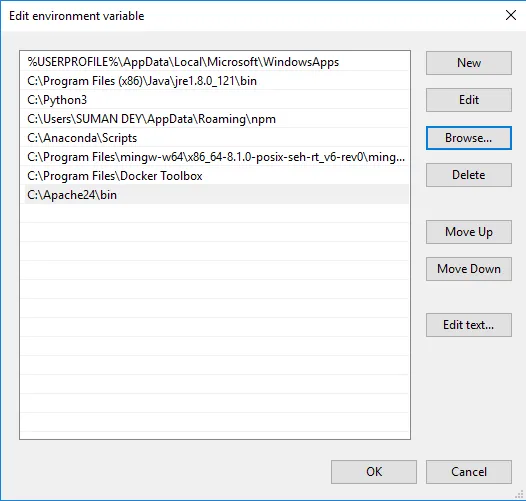
- Cliquez sur Parcourir -> Aller au dossier Apache24 du lecteur C -> Sélectionner le dossier bin -> Cliquez sur OK.
- Nous installerons Apache en tant que service Windows. Exécutez l'invite de commandes en tant qu'administrateur. Tapez httpd –k install et appuyez sur Entrée.
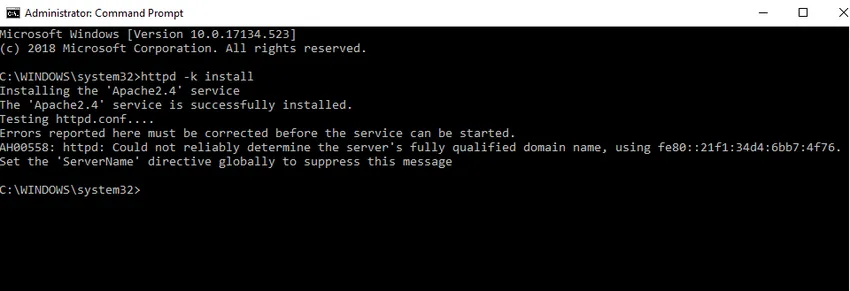
- Nous vérifierons le service d'installation Apache. Cliquez sur l'icône Windows et tapez services. Cliquez sur l'application Services et recherchez le service nommé Apache24.

- Pour démarrer le serveur Apache, faites un clic droit dessus et cliquez sur démarrer. Le statut passera à «En cours d'exécution».
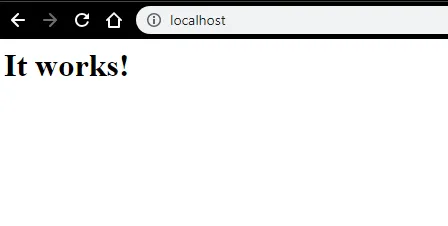
- Nous pouvons tester avec un navigateur. Ouvrez un navigateur et accédez à http: // localhost et appuyez sur Entrée. Un message indiquant "ça marche!" apparaîtra pour confirmer la réussite de l'installation d'Apache.
Articles recommandés
Cela a été un guide sur la façon d'installer Apache. Ici, nous avons discuté des instructions et des différentes étapes pour installer Apache. Vous pouvez également consulter l'article suivant pour en savoir plus -
- Questions d'entretiens chez Apache
- Apache Spark vs Apache Flink
- Apache Hadoop vs Apache Spark
- Apache Kafka vs Flume
- Kafka vs Kinesis | Principales différences