

Introduction à XPath
XPath est un composant principal et central de la norme XSLT. XPath peut être utilisé pour parcourir les éléments, les attributs, le texte, les instructions de traitement, les commentaires, l'espace de noms et le document dans un document XML (Extensible Markup Language). Il s'agit d'une recommandation du W3C qui contient une bibliothèque de plus de 200 fonctions intégrées. XPath est la syntaxe pour définir des parties d'un document XML. XSLT est le langage de feuille de style pour les fichiers XML. Avec XSLT, vous pouvez transformer des documents XML en d'autres formats, comme XHTML. XQuery consiste à interroger des données XML. XQuery est conçu pour interroger tout ce qui peut apparaître en XML, y compris les bases de données. La liaison en XML est divisée en deux parties: XLink et XPointer. XLink et XPointer définissent une manière standard de créer des hyperliens dans des documents XML.
Expression de XPath
XPath permet à différents types d'expressions d'extraire des informations pertinentes du document XML. XPath traite une partie spécifique du document. Il modélise un document XML comme une arborescence de nœuds. Une expression de XPath est une technique de navigation et de sélection de nœuds dans le document.
Les expressions XPath peuvent être utilisées en C, C ++, Python, Java, JavaScript, PHP, schéma XML et de nombreux autres langages. Une expression XPath fait référence à un modèle pour sélectionner un ensemble de nœuds. XPointer utilise ces modèles pour adresser un objectif ou pour effectuer des transformations par XSLT. L'expression XPath spécifie sept types de nœuds qui peuvent être le résultat de l'exécution.
1. Racine
Élément racine d'un document XML. En utilisant les méthodes suivantes, les éléments racine peuvent être trouvés.
- Utiliser un caractère générique (/ *): pour sélectionner le nœud racine
- Utiliser le nom (/ class): pour sélectionner le nœud racine par son nom
- Utiliser le nom avec un caractère générique (/ class / *): pour sélectionner tous les éléments sous le nœud racine
Code:
2. Élément
Noeud d'élément d'un document XML. Voici les moyens de trouver l'élément
- / class / *: utilisé pour sélectionner tous les éléments sous le nœud racine.
- / class / library: utilisé pour sélectionner tous les éléments de bibliothèque du nœud racine.
- // bibliothèque: permet de sélectionner l'intégralité de l'élément de bibliothèque dans le document.
Code:
3. Attributs
Attribut d'un nœud d'élément dans le document XML récupéré et vérifié à l'aide du @ nom-attribut d'un élément.
Code:
4. Texte
Texte d'un nœud d'élément dans le document XML, récupéré et vérifié par le nom d'un élément.
Code:
5. Commentaire
Exemple de commentaire
Code:
Noeud ou liste du noeud à partir de XML
Voici la liste des expressions utiles pour sélectionner un nœud ou la liste du nœud dans un document XML.
- '/': En utilisant cette sélection, commencez à partir du nœud racine.
- '//': l'utilisation de cette sélection commence à partir du nœud actuel qui correspond à la sélection
- '.': Pour sélectionner actuellement cette expression utilisée.
- '..': Pour sélectionner le nœud parent du nœud actuel.
- '@': Pour sélectionner des attributs.
Exemple de XPath
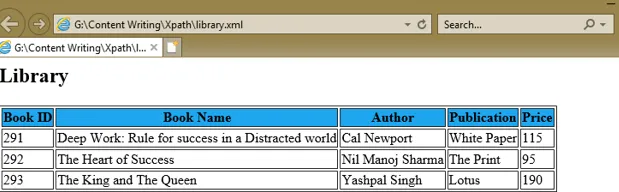
Pour comprendre une expression XPath, nous avons créé un document XML, library.xml, et sa feuille de style document library.xsl qui utilise les expressions XPath sous l'attribut select de diverses balises XSL pour obtenir les valeurs de l'ID du livre, du nom du livre, auteur, publication et prix de chaque nœud de livre.
1. library.xml
Code:
Deep Work: Rule for success in a Distracted world
Cal Newport
White Paper
115
The Heart of Success
Nil Manoj Sharma
The Print
95
The King and The Queen
Yashpal Singh
Lotus
190
2. library.xsl
Code:
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
| | | | |
|---|---|---|---|---|
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
Production:
Avantages de XPath
Voici les avantages de Xpath:
- Les requêtes XPath sont simples à taper et à lire et sont également compactes.
- La syntaxe XPath est facile pour les cas courants et simples.
- Les chaînes de requête sont intégrées facilement dans les scripts, les programmes et les attributs HTML ou XML.
- Les requêtes XPath sont facilement analysées.
- Tout nœud peut reconnaître de façon unique dans un document XML.
- Dans un document XML, l'occurrence de tout chemin ou de tout ensemble de conditions pour les nœuds dans chemin peut être spécifiée.
- Les requêtes renvoient un nombre illimité de résultats, y compris zéro.
- Dans un document XML, les conditions de requête peuvent être calculées à n'importe quel niveau et ne sont pas censées traverser le nœud supérieur d'un document XML.
- Les requêtes XPath renvoient des nœuds uniques, pas des nœuds répétés.
- Dans de nombreux contextes, XPath est utilisé pour fournir des liens vers des nœuds, pour trouver des référentiels et de nombreuses autres applications.
- Pour les programmeurs, les requêtes XPath ne sont pas procédurales mais plus déclaratives. Ils définissent comment les éléments doivent être traversés. Pour obtenir des résultats efficaces, les index et autres structures doivent être utilisés gratuitement par un optimiseur de requête.
Conclusion
XPath est un langage de requête utilisé pour parcourir des éléments, des attributs, du texte à travers un document XML. XPath est largement utilisé pour trouver des éléments ou des attributs particuliers avec des modèles correspondants. Lorsqu'une requête est définie, ces données XML peuvent être représentées sous forme d'arborescence. La représentation hiérarchique des données XML est appelée un arbre. Le sommet de l'arborescence est un nœud racine. Dans une arborescence, chaque attribut, élément, texte, commentaire, chaîne et instruction de traitement correspond à un nœud. Les relations entre les nœuds peuvent être représentées par l'arborescence.
Articles recommandés
Ceci est un guide sur Qu'est-ce que XPath?. Nous discutons ici de l'expression, de la liste, des exemples et des avantages de Xpath. Vous pouvez également consulter nos autres articles connexes pour en savoir plus-
- Qu'est-ce que XPath dans Selenium?
- Qu'est-ce que XML?
- Nouveau cheminement de carrière
- Cheminement de carrière en sécurité de l'information
- Exemples de fonctions intégrées Python